������о�"һ����HASH�㷨"��Consistent Hashing�������ڽ��memcached��Ⱥ�е����������������䶯ʱ��ɢ��ֵ��Ӱ�졣���� ��JAVAEYE�ϵ�һƪ�����У��ҵ������е� KetamaHash �㷨��JAVAʵ�֣�һ�ֻ����������HASH�㷨��������Ϊ�˼������⣬���� JAVA�汾����C#��д��һ�����ŵ���������Ҹ���Ȥ�Ļ��� �������ز���һ�£��������д���������뼰ʱ��֮�ң��Ա��Ҽ�ʱ������
�����Ƕ�Ketama�Ľ��ܣ�
Ketama is an implementation of a consistent hashing algorithm, meaning you can add or remove servers from the memcached pool without causing a complete remap of all keys.
Here’s how it works:
* Take your list of servers (eg: 1.2.3.4:11211, 5.6.7.8:11211, 9.8.7.6:11211)
* Hash each server string to several (100-200) unsigned ints
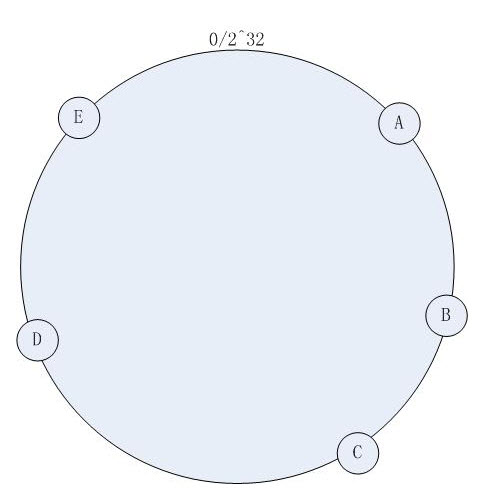
* Conceptually, these numbers are placed on a circle called the continuum. (imagine a clock face that goes from 0 to 2^32)
* Each number links to the server it was hashed from, so servers appear at several points on the continuum, by each of the numbers they hashed to.
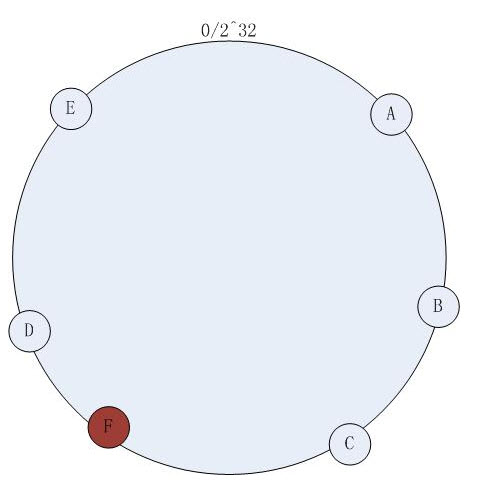
* To map a key->server, hash your key to a single unsigned int, and find the next biggest number on the continuum. The server linked to that number is the correct server for that key.
* If you hash your key to a value near 2^32 and there are no points on the continuum greater than your hash, return the first server in the continuum.
If you then add or remove a server from the list, only a small proportion of keys end up mapping to different servers.
�ҵ����⣬�������ʵ�е����ѧ������ֵ�˼�루ͨ������������ȡֵ����������ͼ���������ͨ������֪��ʵ��㣨memcached����IP�˿ڣ��б����һ��Բ��Ȼ��������ʵ���֮��“����”�����ܶ������ڵ�(�������е�unsigned ints)�� �����û�����ӳ��������ڵ��ϣ��û����������洢λ�����ڸ�����ڵ������ʵ�������������ϣ��������������Ʒֲ������ȣ�����ȵؼ�С����������ʱ�Ļ������·ֲ�������ͼ��
���������ӽ��ʱ��
����ƪ������˵���ܽ�һ���Թ�ϣ(Consistent Hashing) ����
Consistent Hashing����ȵ�������hash�������·ֲ�������Ҫȡ�ñȽϺõĸ��ؾ����Ч���������ڷ����������Ƚ��ٵ�ʱ����Ҫ��������ڵ�����֤�������ܾ��ȵķֲ���Բ���ϡ���Ϊʹ��һ���hash��������������ӳ��ص�ķֲ��dz������ȡ�ʹ������ڵ��˼�룬Ϊÿ�������ڵ㣨����������Բ�Ϸ���100��200���㡣�����������Ʒֲ������ȣ�����ȵؼ�С����������ʱ�Ļ������·ֲ����û�����ӳ��������ڵ��ϣ��ͱ�ʾ�û����������洢λ�����ڸ�����ڵ������ʵ�������������ϡ�
�˽���ԭ�������濴һ�¾���ʵ�֡�
JAVAʵ�ִ���ȡ��Spy Memcached client�е��࣬ԭ�ĵ�����Ҳ�����ܵĶԴ������ע��˵������������ʣ�˲���ʱ�䡣
��������Ӧ��.NETʵ�֣�ע�Ͳο�JAVA�汾��:
public class KetamaNodeLocator
{
//ԭ���е�JAVA��TreeMapʵ����Comparator������������ͼʡ�£�ֱ������net�µ�SortedList������Comparer�ӿڷ�����
private SortedList<long, string> ketamaNodes = new SortedList<long, string>();
private HashAlgorithm hashAlg;
private int numReps = 160;
//�˴�������JAVA������������Ϊʹ�õľ�̬���������Բ��ٴ���HashAlgorithm alg����
public KetamaNodeLocator(List<string> nodes, int nodeCopies)
{
ketamaNodes = new SortedList<long, string>();
numReps = nodeCopies;
//�����нڵ㣬����nCopies��������
foreach (string node in nodes)
{
//ÿ�ĸ�������Ϊһ��
for (int i = 0; i < numReps / 4; i++)
{
//getKeyForNode����Ϊ����������õ�Ωһ����
byte[] digest = HashAlgorithm.computeMd5(node + i);
/** Md5��һ��16�ֽڳ��ȵ����飬��16�ֽڵ�����ÿ�ĸ��ֽ�һ�飬�ֱ��Ӧһ�������㣬�����Ϊʲô������������ĸ�����һ���ԭ��*/
for (int h = 0; h < 4; h++)
{
long m = HashAlgorithm.hash(digest, h);
ketamaNodes[m] = node;
}
}
}
}
public string GetPrimary(string k)
{
byte[] digest = HashAlgorithm.computeMd5(k);
string rv = GetNodeForKey(HashAlgorithm.hash(digest, 0));
return rv;
}
string GetNodeForKey(long hash)
{
string rv;
long key = hash;
//����ҵ�����ڵ㣬ֱ��ȡ�ڵ㣬����
if (!ketamaNodes.ContainsKey(key))
{
//�õ����ڵ�ǰkey���Ǹ���Map��Ȼ�����ȡ����һ��key�����Ǵ���������������Ǹ�key ˵�����: http://www.javaeye.com/topic/684087
var tailMap = from coll in ketamaNodes
where coll.Key > hash
select new { coll.Key };
if (tailMap == null || tailMap.Count() == 0)
key = ketamaNodes.FirstOrDefault().Key;
else
key = tailMap.FirstOrDefault().Key;
}
rv = ketamaNodes[key];
return rv;
}
}
����Ĵ�����JAVA��������ͬ����ʹ�þ�̬����ʵ�֣�
public class HashAlgorithm
{
public static long hash(byte[] digest, int nTime)
{
long rv = ((long)(digest[3 + nTime * 4] & 0xFF) << 24)
| ((long)(digest[2 + nTime * 4] & 0xFF) << 16)
| ((long)(digest[1 + nTime * 4] & 0xFF) << 8)
| ((long)digest[0 + nTime * 4] & 0xFF);
return rv & 0xffffffffL; /* Truncate to 32-bits */
}
/**
* Get the md5 of the given key.
*/
public static byte[] computeMd5(string k)
{
MD5 md5 = new MD5CryptoServiceProvider();
byte[] keyBytes = md5.ComputeHash(Encoding.UTF8.GetBytes(k));
md5.Clear();
//md5.update(keyBytes);
//return md5.digest();
return keyBytes;
}
}
������.net�汾�µIJ��Խ��
�ֲ�ƽ���Բ���:����������ɵ��ڶ�key�Ƿ��ƽ���ֲ�����������ϲ��Խ������:
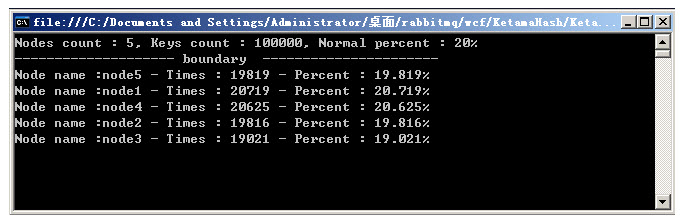
������һ���Dz���˵�����ڵ���Ŀ���ܹ��ж���key��ÿ���ڵ�Ӧ�÷���key�ı����Ƕ��١�������ÿ�������䵽key����Ŀ�ͱ����� ��β��Ժ��֣����Hash�㷨�Ľڵ�ֲ����ڱ����������ǻ���
�ڵ���ɾ����:�ڻ��ϲ���N����㣬ÿ���ڵ�nCopies�������㡣��������ڶ�key������ɾ�ڵ�ʱ������ͬһ��keyѡ����ͬ�ڵ�ĸ��ʣ������������:
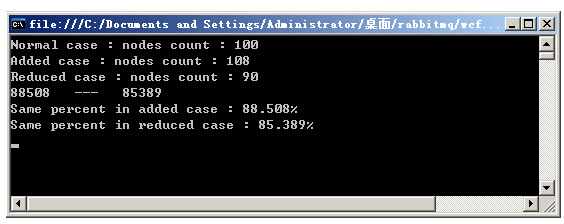
�������зֱ�������������ڵ����ӣ��ڵ�ɾ������µĽڵ���Ŀ���������б�ʾ�ڽڵ����Ӻ�ɾ������£�ͬһ��key��������ͬ�ڵ��ϵı���(������)��
���������˼�����ɾ����������������֤��JAVA��λ������˵��������
��β��Ժ��֣�������������Ŀ�������Ľڵ������йء�ͬ����ɾ�����Ŀ����£�����ʱ�����ʸߡ�ͬ���ڵ���Ŀ����ɾ���Խ�٣�������Խ�ߡ���Щ����ʵ����������
���ﻹ��һЩ���ӣ����ǽ��ܺ�����Consistent Hashing�ģ�����Ȥ�����ѿ��Կ�һ�£��Ǻǣ�)
 ϲ��
ϲ��  ��
�� �ѹ�
�ѹ� ��
�� ��
�� ����
����