
����
�������ʽ��regular expression��������һ��“�ַ���”������һ��������Ȼ��ȥ��֤��һ��“�ַ���”�Ƿ����������������� ����ʽ“ab+” ������������“һ�� 'a' �� ����� 'b' ”����ô 'ab', 'abb', 'abbbbbbbbbb' ���������������
�������ʽ������������1����֤�ַ����Ƿ����ָ��������������֤�Ƿ��ǺϷ����ʼ���ַ����2�����������ַ�������һ�������ı��в��ҷ���ָ���������ַ������Ȳ��ҹ̶��ַ����������㡣��3�������滻������ͨ���滻��ǿ��
�������ʽѧϰ������ʵ�Ǻܼģ�����ļ�����Ϊ����ĸ���Ҳ���������⡣֮���Ժܶ��˸о��������ʽ�Ƚϸ��ӣ�һ��������Ϊ��������ĵ�û��������dz����ؽ��⣬������û��ע���Ⱥ�˳�����ߵ�����������ѣ���һ���棬���������Դ����ĵ�һ�㶼Ҫ���������еĹ��ܣ�Ȼ���ⲿ�����еĹ��ܲ�������������Ҫ����ġ�
�����е�ÿһ�������������Ե�����뵽����ҳ����в��ԡ��л���˵����ʼ��
1. �������ʽ����
1.1 ��ͨ�ַ�
��ĸ�����֡����֡��»��ߡ��Լ�����½���û�����ⶨ��ı����ţ�����"��ͨ�ַ�"������ʽ�е���ͨ�ַ�����ƥ��һ���ַ�����ʱ��ƥ����֮��ͬ��һ���ַ���
����1������ʽ "c"����ƥ���ַ��� "abcde" ʱ��ƥ�����ǣ��ɹ���ƥ�䵽�������ǣ�"c"��ƥ�䵽��λ���ǣ���ʼ��2��������3����ע���±��0��ʼ���Ǵ�1��ʼ����ǰ������ԵIJ�ͬ�����ܲ�ͬ��
����2������ʽ "bcd"����ƥ���ַ��� "abcde" ʱ��ƥ�����ǣ��ɹ���ƥ�䵽�������ǣ�"bcd"��ƥ�䵽��λ���ǣ���ʼ��1��������4��
1.2 ��ת���ַ�
һЩ������д���ַ���������ǰ��� "\" �ķ�������Щ�ַ���ʵ���Ƕ��Ѿ���֪�ˡ�

��������һЩ�ں���½����������ô��ı����ţ���ǰ��� "\" �ʹ����÷��ű��������磺^, $ �����������壬���Ҫ��ƥ���ַ����� "^" �� "$" �ַ��������ʽ����Ҫд�� "\^" �� "\$"��

��Щת���ַ���ƥ�䷽���� "��ͨ�ַ�" �����Ƶġ�Ҳ��ƥ����֮��ͬ��һ���ַ���
����1������ʽ "\$d"����ƥ���ַ��� "abc$de" ʱ��ƥ�����ǣ��ɹ���ƥ�䵽�������ǣ�"$d"��ƥ�䵽��λ���ǣ���ʼ��3��������5��
1.3 �ܹ��� '�����ַ�' ƥ��ı���ʽ
�������ʽ�е�һЩ��ʾ����������ƥ�� '�����ַ�' ���е�����һ���ַ������磬����ʽ "\d" ����ƥ������һ�����֡���Ȼ����ƥ�����������ַ�������ֻ����һ�������Ƕ������ͺñ����˿���ʱ��С�����Դ�������һ���ƣ�����ֻ�ܴ���һ���ơ�

����1������ʽ "\d\d"����ƥ�� "abc123" ʱ��ƥ��Ľ���ǣ��ɹ���ƥ�䵽�������ǣ�"12"��ƥ�䵽��λ���ǣ���ʼ��3��������5��
����2������ʽ "a.\d"����ƥ�� "aaa100" ʱ��ƥ��Ľ���ǣ��ɹ���ƥ�䵽�������ǣ�"aa1"��ƥ�䵽��λ���ǣ���ʼ��1��������4��
1.4 �Զ����ܹ�ƥ�� '�����ַ�' �ı���ʽ
ʹ�÷����� [ ] ����һϵ���ַ����ܹ�ƥ����������һ���ַ����� [^ ] ����һϵ���ַ������ܹ�ƥ�������ַ�֮�������һ���ַ���ͬ���ĵ�������Ȼ����ƥ����������һ��������ֻ����һ�������Ƕ����
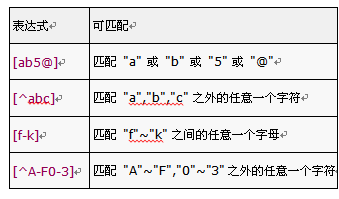
����1������ʽ "[bcd][bcd]" ƥ�� "abc123" ʱ��ƥ��Ľ���ǣ��ɹ���ƥ�䵽�������ǣ�"bc"��ƥ�䵽��λ���ǣ���ʼ��1��������3��
����2������ʽ "[^abc]" ƥ�� "abc123" ʱ��ƥ��Ľ���ǣ��ɹ���ƥ�䵽�������ǣ�"1"��ƥ�䵽��λ���ǣ���ʼ��3��������4��
1.5 ����ƥ��������������
ǰ���½��н����ı���ʽ��������ֻ��ƥ��һ���ַ��ı���ʽ�����ǿ���ƥ������ַ���������һ���ı���ʽ����ֻ��ƥ��һ�Ρ����ʹ�ñ���ʽ�ټ�������ƥ�������������ţ���ô�����ظ���д����ʽ�Ϳ����ظ�ƥ�䡣
ʹ�÷����ǣ�"��������"����"�����εı���ʽ"��ߡ����磺"[bcd][bcd]" ����д�� "[bcd]{2}"��

����1������ʽ "\d+\.?\d*" ��ƥ�� "It costs $12.5" ʱ��ƥ��Ľ���ǣ��ɹ���ƥ�䵽�������ǣ�"12.5"��ƥ�䵽��λ���ǣ���ʼ��10��������14��
����2������ʽ "go{2,8}gle" ��ƥ�� "Ads by goooooogle" ʱ��ƥ��Ľ���ǣ��ɹ���ƥ�䵽�������ǣ�"goooooogle"��ƥ�䵽��λ���ǣ���ʼ��7��������17��
1.6 ����һЩ��������������������
һЩ�����ڱ���ʽ�д���������������壺

��һ��������˵����Ȼ�Ƚϳ�����ˣ���������������⡣
����1������ʽ "^aaa" ��ƥ�� "xxx aaa xxx" ʱ��ƥ�����ǣ�ʧ�ܡ���Ϊ "^" Ҫ�����ַ�����ʼ�ĵط�ƥ�䣬��ˣ�ֻ�е� "aaa" λ���ַ����Ŀ�ͷ��ʱ��"^aaa" ����ƥ�䣬���磺"aaa xxx xxx"��
����2������ʽ "aaa$" ��ƥ�� "xxx aaa xxx" ʱ��ƥ�����ǣ�ʧ�ܡ���Ϊ "$" Ҫ�����ַ��������ĵط�ƥ�䣬��ˣ�ֻ�е� "aaa" λ���ַ����Ľ�β��ʱ��"aaa$" ����ƥ�䣬���磺"xxx xxx aaa"��
����3������ʽ ".\b." ��ƥ�� "@@@abc" ʱ��ƥ�����ǣ��ɹ���ƥ�䵽�������ǣ�"@a"��ƥ�䵽��λ���ǣ���ʼ��2��������4��
��һ��˵����"\b" �� "^" �� "$" ���ƣ�������ƥ���κ��ַ���������Ҫ������ƥ����������λ�õ��������ߣ�����һ���� "\w" ��Χ����һ���� ��"\w" �ķ�Χ��
����4������ʽ "\bend\b" ��ƥ�� "weekend,endfor,end" ʱ��ƥ�����ǣ��ɹ���ƥ�䵽�������ǣ�"end"��ƥ�䵽��λ���ǣ���ʼ��15��������18��

����6������ʽ "(go\s*)+" ��ƥ�� "Let's go go go!" ʱ��ƥ�����ǣ��ɹ���ƥ�䵽�����ǣ�"go go go"��ƥ�䵽��λ���ǣ���ʼ��6��������14��
����7������ʽ "��(\d+\.?\d*)" ��ƥ�� "��10.9,��20.5" ʱ��ƥ��Ľ���ǣ��ɹ���ƥ�䵽�������ǣ�"��20.5"��ƥ�䵽��λ���ǣ���ʼ��6��������10��������ȡ���ŷ�Χƥ�䵽�������ǣ�"20.5"��
|
����ʽ
|
ƥ����
|
|
"\w+" ��ƥ���һ�� "d" ֮��������ַ� "xxxdxxxd"
|
|
|
"\w+" ��ƥ���һ�� "d" �����һ�� "d" ֮��������ַ� "xxxdxxx"����Ȼ "\w+" Ҳ�ܹ�ƥ�������һ�� "d"������Ϊ��ʹ��������ʽƥ��ɹ���"\w+" ���� "�ó�" �������ܹ�ƥ������һ�� "d"
|
������ƥ�������������ź��ټ���һ�� "?" �ţ������ʹƥ����������ı���ʽ�������ٵ�ƥ�䣬ʹ��ƥ��ɲ�ƥ��ı���ʽ�������ܵ� "��ƥ��"������ƥ��ԭ����� "��̰��" ģʽ��Ҳ���� "��ǿ" ģʽ�������ƥ��ͻᵼ����������ʽƥ��ʧ�ܵ�ʱ����̰��ģʽ���ƣ���̰��ģʽ����С�ȵ���ƥ��һЩ����ʹ��������ʽƥ��ɹ����������£�����ı� "dxxxdxxxd" ������
|
����ʽ
|
ƥ����
|
|
"\w+?" ���������ٵ�ƥ���һ�� "d" ֮����ַ�������ǣ�"\w+?" ֻƥ����һ�� "x"
|
|
|
Ϊ������������ʽƥ��ɹ���"\w+?" ���ò�ƥ�� "xxx" �ſ����ú�ߵ� "d" ƥ�䣬�Ӷ�ʹ��������ʽƥ��ɹ�����ˣ�����ǣ�"\w+?" ƥ�� "xxx"
|
����1������ʽ "<td>(.*)</td>" ���ַ��� "<td><p>aa</p></td> <td><p>bb</p></td>" ƥ��ʱ��ƥ��Ľ���ǣ��ɹ���ƥ�䵽�������� "<td><p>aa</p></td> <td><p>bb</p></td>" �����ַ���������ʽ�е� "</td>" �����ַ��������һ�� "</td>" ƥ�䡣
����2�����֮�£�����ʽ "<td>(.*?)</td>" ƥ�����1��ͬ�����ַ���ʱ����ֻ�õ� "<td><p>aa</p></td>"���ٴ�ƥ����һ��ʱ�����Եõ��ڶ��� "<td><p>bb</p></td>"��
��ʵ��"С���Ű����ı���ʽ��ƥ�䵽���ַ���" ��������ƥ�������ſ���ʹ�ã���ƥ�������Ҳ����ʹ�á�����ʽ��ߵIJ��֣���������ǰ�� "�����ڵ���ƥ���Ѿ�ƥ�䵽���ַ���"�����÷����� "\" ����һ�����֡�"\1" ���õ�1��������ƥ�䵽���ַ�����"\2" ���õ�2��������ƥ�䵽���ַ���……�Դ����ƣ����һ�������ڰ�����һ�����ţ�����������������š����仰˵����һ�Ե������� "(" ��ǰ������һ�Ծ�������š�
����1������ʽ "('|")(.*?)(\1)" ��ƥ�� " 'Hello', "World" " ʱ��ƥ�����ǣ��ɹ���ƥ�䵽�������ǣ�" 'Hello' "���ٴ�ƥ����һ��ʱ������ƥ�䵽 " "World" "��
����2������ʽ "(\w)\1{4,}" ��ƥ�� "aa bbbb abcdefg ccccc 111121111 999999999" ʱ��ƥ�����ǣ��ɹ���ƥ�䵽�������� "ccccc"���ٴ�ƥ����һ��ʱ�����õ� 999999999���������ʽҪ�� "\w" ��Χ���ַ������ظ�5�Σ�ע���� "\w{5,}" ֮���������
����3������ʽ "<(\w+)\s*(\w+(=('|").*?\4)?\s*)*>.*?</\1>" ��ƥ�� "<td id='td1' style="bgcolor:white"></td>" ʱ��ƥ�����dzɹ������ "<td>" �� "</td>" ����ԣ����ƥ��ʧ�ܣ�����ij�������ԣ�Ҳ����ƥ��ɹ���
��ʽ��"(?=xxxxx)"���ڱ�ƥ����ַ����У����������� "��϶" ���� "��ͷ" ���ӵ������ǣ����ڷ�϶���Ҳ࣬�����ܹ�ƥ���� xxxxx �ⲿ�ֵı���ʽ����Ϊ��ֻ���ڴ���Ϊ�����϶�ϸ��ӵ�����������������Ӱ���ߵı���ʽȥ����ƥ�������϶֮����ַ���������� "\b"��������ƥ���κ��ַ���"\b" ֻ�ǽ����ڷ�϶֮ǰ��֮����ַ�ȡ��������һ���жϣ�����Ӱ���ߵı���ʽ��������ƥ�䡣
����1������ʽ "Windows (?=NT|XP)" ��ƥ�� "Windows 98, Windows NT, Windows 2000" ʱ����ֻƥ�� "Windows NT" �е� "Windows "�������� "Windows " ������ƥ�䡣
����2������ʽ "(\w)((?=\1\1\1)(\1))+" ��ƥ���ַ��� "aaa ffffff 999999999" ʱ��������ƥ��6��"f"��ǰ4��������ƥ��9��"9"��ǰ7�����������ʽ���Զ���ɣ��ظ�4�����ϵ���ĸ���֣���ƥ����ʣ�����2λ֮ǰ�IJ��֡���Ȼ���������ʽ���Բ�����д���ڴ˵�Ŀ������Ϊ��ʾ֮�á�
����3������ʽ "((?!\bstop\b).)+" ��ƥ�� "fdjka ljfdl stop fjdsla fdj" ʱ������ͷһֱƥ�䵽 "stop" ֮ǰ��λ�ã�����ַ�����û�� "stop"����ƥ�������ַ�����
����4������ʽ "do(?!\w)" ��ƥ���ַ��� "done, do, dog" ʱ��ֻ��ƥ�� "do"���ڱ��������У�"do" ���ʹ�� "(?!\w)" ��ʹ�� "\b" Ч����һ���ġ�
�����ָ�ʽ�ĸ��������Ԥ���������Ƶģ�����Ԥ����Ҫ��������ǣ����ڷ�϶�� "���"�����ָ�ʽ�ֱ�Ҫ������ܹ�ƥ��ͱ��벻�ܹ�ƥ��ָ������ʽ��������ȥ�ж��Ҳࡣ�� "����Ԥ����" һ�����ǣ����Ƕ��Ƕ����ڷ�϶��һ�ָ�����������������ƥ���κ��ַ���
����5������ʽ "(?<=\d{4})\d+(?=\d{4})" ��ƥ�� "1234567890123456" ʱ����ƥ�����ǰ4�����ֺͺ�4������֮����м�8�����֡����� JScript.RegExp ��֧�ַ���Ԥ��������ˣ������������ܹ�������ʾ���ܶ��������������֧�ַ���Ԥ���������磺Java 1.4 ���ϵ� java.util.regex ����.NET ��System.Text.RegularExpressions �����ռ䣬�Լ���վ�Ƽ���������õ� DEELX ����������
|
��ʽ
|
�ַ���Χ
|
|
\xXX
|
|
|
\uXXXX
|
|
����ʽ
|
��ƥ��
|
|
\S
|
|
|
\D
|
|
|
\W
|
|
|
\B
|
|
�ַ�
|
˵��
|
|
^
|
ƥ�������ַ����Ŀ�ʼλ�á�Ҫƥ�� "^" �ַ���������ʹ�� "\^"
|
|
$
|
ƥ�������ַ����Ľ�βλ�á�Ҫƥ�� "$" �ַ���������ʹ�� "\$"
|
|
( )
|
���һ���ӱ���ʽ�Ŀ�ʼ�ͽ���λ�á�Ҫƥ��С���ţ���ʹ�� "\(" �� "\)"
|
|
[ ]
|
�����Զ����ܹ�ƥ�� '�����ַ�' �ı���ʽ��Ҫƥ�������ţ���ʹ�� "\[" �� "\]"
|
|
{ }
|
����ƥ������ķ��š�Ҫƥ������ţ���ʹ�� "\{" �� "\}"
|
|
.
|
ƥ����˻��з���\n�����������һ���ַ���Ҫƥ��С���㱾������ʹ�� "\."
|
|
?
|
����ƥ�����Ϊ 0 �λ� 1 �Ρ�Ҫƥ�� "?" �ַ���������ʹ�� "\?"
|
|
+
|
����ƥ�����Ϊ���� 1 �Ρ�Ҫƥ�� "+" �ַ���������ʹ�� "\+"
|
|
*
|
����ƥ�����Ϊ 0 �λ�����Ρ�Ҫƥ�� "*" �ַ���������ʹ�� "\*"
|
|
|
|
�������߱���ʽ֮�� "��" ��ϵ��ƥ�� "|" ��������ʹ�� "\|"
|
|
����ʽ����
|
˵��
|
|
Ignorecase
|
Ĭ������£�����ʽ�е���ĸ��Ҫ���ִ�Сд�ġ�����Ϊ Ignorecase ��ʹƥ��ʱ�����ִ�Сд���еı���ʽ���棬�� "��Сд" ���������� UNICODE ��Χ�Ĵ�Сд��
|
|
Singleline
|
Ĭ������£�С���� "." ƥ����˻��з���\n��������ַ�������Ϊ Singleline ��ʹС�����ƥ��������з����ڵ������ַ���
|
|
Multiline
|
Ĭ������£�����ʽ "^" �� "$" ֻƥ���ַ����Ŀ�ʼ���ͽ�β��λ�á��磺
��xxxxxxxxx��\n ��xxxxxxxxx�� ����Ϊ Multiline ����ʹ "^" ƥ�����⣬������ƥ�任�з�֮����һ�п�ʼǰ����λ�ã�ʹ "$" ƥ�����⣬������ƥ�任�з�֮ǰ��һ�н�������λ�á� |
|
Global
|
��Ҫ�ڽ�����ʽ�����滻ʱ�����ã�����Ϊ Global ��ʾ�滻���е�ƥ�䡣
|

 ϲ��
ϲ��  ��
�� �ѹ�
�ѹ� ��
�� ��
�� ����
����



