Trie树的实现
Trie树是一种形似树的数据结构,它的每个节点都包含一个指针数组,假设,我们要构建一个26个字母的Trie树,那么每一个指针对应着字母表里的一个字母。从根节点开始,我们只要依次找到目标单词里下一个字母对应的指针,就可以一步步查找目标了。假设,我们要把字符串AB,ABBA,ABCD和BCD插入到Trie树中,由于Trie树的根节点不保存任何字母,我们从根节点的直接后继开始保存字母。如下图所示,我们在Trie树的第二层中保存了字母A和B,第三层中保存了B和C,其中B被标记为深蓝色表示单词AB已经插入完成。
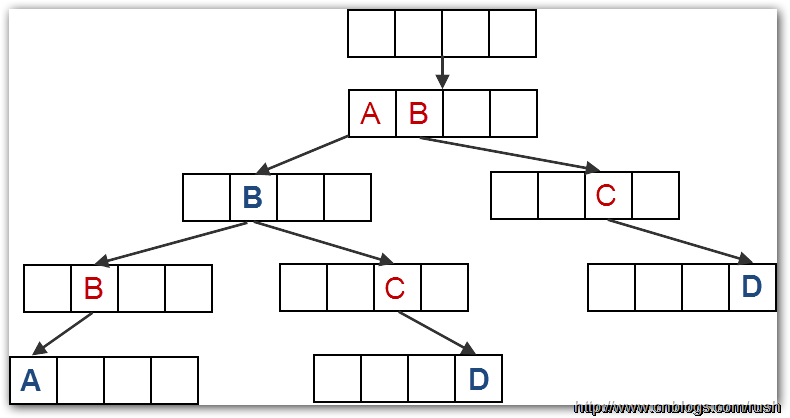
图2 Trie树的实现
我们发现由于Trie的每个节点都有一个长度为26指针数组,但我们知道并不是每个指针数组都保存记录,空的指针数组导致内存空间的浪费。
假设,我们要设计一个翻译软件,翻译软件少不了查词功能,而且当用户输入要查询的词汇时,软件会提示相似单词,让用户选择要查询的词汇,这样用户就无需输入完整词汇就能进行查询,而且用户体验更好。
我们将使用Trie树结构存储和检索单词,从而实现词汇的智能提示功能,这里我们只考虑26英文字母匹配的实现,所以我们将构建一棵26叉树。
由于每个节点下一层都包含26个节点,那么我们在节点类中添加节点属性,节点类的具体实现如下:
/// <summary>
/// The node type.
/// Indicates the word completed or not.
/// </summary>
public enum NodeType
{
COMPLETED,
UNCOMPLETED
};
/// <summary>
/// The tree node.
/// </summary>
public class Node
{
const int ALPHABET_SIZE = 26;
internal char Word { get; set; }
internal NodeType Type { get; set; }
internal Node[] Child;
/// <summary>
/// Initializes a new instance of the <see cref="Node"/> class.
/// </summary>
/// <param name="word">The word.</param>
/// <param name="nodeType">Type of the node.</param>
public Node(char word, NodeType nodeType)
{
this.Word = word;
this.Type = nodeType;
this.Child = new Node[ALPHABET_SIZE];
}
}上面我们定义一个枚举类型NodeType,它用来标记词汇是否插入完成;接着,我们定义了一个节点类型Node,它包含两个属性Word和Type,Word用来保存当前节点的字母,Type用来标记当前节点是否插入完成。
接下来,我们要定义Trie树类型,并且添加Insert(),Find()和FindSimilar()方法。
/// <summary>
/// The trie tree entity.
/// </summary>
public class Trie
{
const int ALPHABET_SIZE = 26;
private Node _root;
private HashSet<string> _hashSet;
public Trie()
{
_root = CreateNode(' ');
}
public Node CreateNode(char word)
{
var node = new Node(word, NodeType.UNCOMPLETED);
return node;
}
/// <summary>
/// Inserts the specified node.
/// </summary>
/// <param name="node">The node.</param>
/// <param name="word">The word need to insert.</param>
private void Insert(ref Node node, string word)
{
Node temp = node;
foreach (char t in word)
{
if (null == temp.Child[this.CharToIndex(t)])
{
temp.Child[this.CharToIndex(t)] = this.CreateNode(t);
}
temp = temp.Child[this.CharToIndex(t)];
}
temp.Type = NodeType.COMPLETED;
}
/// <summary>
/// Inserts the specified word.
/// </summary>
/// <param name="word">Retrieval word.</param>
public void Insert(string word)
{
if (string.IsNullOrEmpty(word))
{
throw new ArgumentException("word");
}
Insert(ref _root, word);
}
/// <summary>
/// Finds the specified word.
/// </summary>
/// <param name="word">Retrieval word.</param>
/// <returns>The tree node.</returns>
public Node Find(string word)
{
if (string.IsNullOrEmpty(word))
{
throw new ArgumentException("word");
}
int i = 0;
Node temp = _root;
var words = new HashSet<string>();
while (i < word.Length)
{
if (null == temp.Child[this.CharToIndex(word[i])])
{
return null;
}
temp = temp.Child[this.CharToIndex(word[i++])];
}
if (temp != null && NodeType.COMPLETED == temp.Type)
{
_hashSet = new HashSet<string> { word };
return temp;
}
return null;
}
/// <summary>
/// Finds the simlar word.
/// </summary>
/// <param name="word">The words have same prefix.</param>
/// <returns>The collection of similar words.</returns>
public HashSet<string> FindSimilar(string word)
{
Node node = Find(word);
DFS(word, node);
return _hashSet;
}
/// <summary>
/// DFSs the specified prefix.
/// </summary>
/// <param name="prefix">Retrieval prefix.</param>
/// <param name="node">The node.</param>
private void DFS(string prefix, Node node)
{
for (int i = 0; i < ALPHABET_SIZE; i++)
{
if (node.Child[i] != null)
{
DFS(prefix + node.Child[i].Word, node.Child[i]);
if (NodeType.COMPLETED == node.Child[i].Type)
{
_hashSet.Add(prefix + node.Child[i].Word);
}
}
}
}
/// <summary>
/// Converts char to index.
/// </summary>
/// <param name="ch">The char need to convert.</param>
/// <returns>The index.</returns>
private int CharToIndex(char ch)
{
return ch - 'a';
}
}上面我们,定义了Trie树类,它包含两个字段分别是:_root和_hashSet,_root用来保存Trie树的根节点,我们使用_hashSet保存前缀匹配的所有单词。
接着,我们在Trie树类中定义了CreateNode(),Insert(),Find(),FindSimilar()和DFS()等方法。
CreateNode()方法用来创建树的节点,Insert()方法把节点插入树中,Find()和FindSimilar()方法用来查找指定单词,DFS()方法是查找单词的具体实现,它通过深度搜索的方法遍历节点查找匹配的单词,最后把匹配的单词保存到_hashSet中。
接下来,我们创建一棵Trie树,然后把两千个英语单词插入到Trie树中,最后我们查找前缀为“the”的所有单词包括前缀本身。
public class Program
{
public static void Main()
{
// Creates a file object.
var file = File.ReadAllLines(Environment.CurrentDirectory + "//1.txt");
// Creates a trie tree object.
var trie = new Trie();
foreach (var item in file)
{
var sp = item.Split(new char[] { ' ' }, StringSplitOptions.RemoveEmptyEntries);
// Inserts word into to the tree.
trie.Insert(sp.LastOrDefault().ToLower());
////ternaryTree.Insert(sp.LastOrDefault().ToLower());
}
var similarWords = trie.FindSimilar("jk");
foreach (var similarWord in similarWords)
{
Console.WriteLine("Similar word: {0}", similarWord);
}
}
}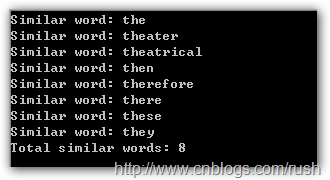
图3 匹配词结果
我们在1.txt文本文件中通过正则表达式(^:z the+)查找前缀为the的所有单词,恰好就是上面8个单词。
本文导航
- 第1页: 首页
- 第2页: Trie树的实现
- 第3页: Ternary Tree的定义和实现
- 第4页: Ternary Tree的应用
 喜欢
喜欢  顶
顶 难过
难过 囧
囧 围观
围观 无聊
无聊