���ĵ�Ŀ����������ż�Webǰ�˿�����Ա��
���Ľ�����CSSѡ�������ʽ����Ļ���ԭ����CSSѡ������漸����ǰ�˿�����Աÿ����ʹ�õĹ��ߡ����Ľ���һ����ʵ�ָ�����ĸ��ֲ��ԡ����ȣ����ǽ��ܻ���W3C��API�ķ�����
W3C����Slectors API
�ܹ�֧�ֵ�ƽ̨�� Safari 3+, Firefox 3.1+, Internet Explorer 8+, Chrome and Opera 10+
������õķ�����
querySelector���ú�������һ��CSSѡ����ַ����������ҵ��ĵ�һ��Ԫ�أ����û���ҵ���null��
querySelectorAll���ú�������һ��CSSѡ����ַ����������ҵ�������Ԫ�صļ���(NodeList)��
�������������������е�DOMԪ�أ�DOM�ĵ������Լ�DOM�ĵ�Ƭ�Σ�fragment�������ϡ�
<div id="test"> <b>Hello</b>, I'm a ninja! </div> <div id="test2"></div>
<script>
window.onload = function () {
var divs = document.querySelectorAll("body > div");
assert(divs.length === 2, "Two divs found using a CSS selector.");
var b = document.getElementById("test")
.querySelector("b:only-child");
assert(b,
"The bold element was found relative to another element.");
};
</script>�������ӵ�һ��ȱ�������������������CSSѡ�����֧�֣��ϰ汾IE��Ъ���ˣ�����˿��Կ���ʹ����ijԪ����Ϊ���ڵ���ӽڵ�IJ�ѯ���������¡�
<script>
window.onload = function () {
var b = document.getElementById("test").querySelector("div b");
assert(b, "Only the last part of the selector matters.");
};
</script>���������и����⣬����ijԪ����Ϊ���ڵ���ӽڵ�IJ�ѯʱ��query����ֻ������ұߵIJ����Dz��ǰ����ڸ��ڵ��ע�#test����ѹ����û��div��ǩ������query���������˲�ѯ�ַ�����ǰ�沿�֡�
�������ȷʵ���������������CSSѡ������������Ч��������������Ҫ��һЩ������������ļ����ǣ���ʱ����һ����id���Ǹ����ڵ�Ԫ�شӶ�ǿ�еذ�������������ݡ��������¡�
<script>
(function () {
var count = 1;
this.rootedQuerySelectorAll = function (elem, query) {
var oldID = elem.id;
elem.id = "rooted" + (count++);
try {
return elem.querySelectorAll("#" + elem.id + " " + query);
} catch (e) {
throw e;
} finally {
elem.id = oldID;
}
};
})();
window.onload = function () {
var b = rootedQuerySelectorAll( document.getElementById("test"), "div b");
assert(b.length === 0, "The selector is now rooted properly.");
};
</script>������������������Ҫע����¼��㣺
���ȣ�Ҫ����Ԫ��һ��ȫ��Ψһ��id�������Ҫ���游Ԫ��ԭʼ��id��Ȼ������ȫ��Ψһ��id���ӵ���ѯ�ַ����С�
���ŵ���β���־���ȥ�������ӵ��Ǹ�id�ͷ��ز�ѯ�������������п��ܻ���һ��API�쳣�׳��������������Ϊѡ��������������������֧�ֵ�ѡ���������ˣ�����Ҫ�������try/catch�����סAPI������䣬��Ҫ��finnally���Ӿ��л�ԭ��Ԫ�ص�ԭʼid������ܻᷢ�֣�����������JavaScript���������һ���ط���������Ȼ������try������Ѿ�return�ˣ�����finnally�Ӿ仹��Ҫ��ִ�еģ��ڽ��ֵ������return�����ú���ǰ����
ѡ����API���Կ�������W3C�������ǰ;����API�ˡ�һ�����������֧��CSS3�������پ���CSS3ѡ������Ժ������Խ�ʡ�����Աʹ�ô�����JavaScript���롣
ʹ�� XPath Ѱ��Ԫ��
XPath��һ�ֿ�����DOM�ĵ��в�ѯ�ڵ�����ԡ���������CSSѡ�������ǿ���������е������ (Firefox,Safari 3+, Opera 9+, Chrome)���ṩ�˶�XPath�IJ��ֺ���ʵ�֣�������HTML�ĵ��в���Ԫ�ء� Internet Explorer 6��֮ǰ�İ汾ֻ��ʹ��XPath����XML�ĵ���������HTML�ĵ�����
Xpath����ʽ�ȸ��ӵ�CSSѡ���ִ�п졣���ǣ�������ʵ��һ����DOM������ʽ��CSSѡ�������ʱ������Ҫ���������֧���Եķ��ա��ڶ��ڼ�CSSѡ�����Xpath��ʧȥ��Խ���ˡ�
������ǿ���ʹ��һ����ֵ����ʹ��Xpath����������������Ǿ�����Xpath��������ֵ�����ڿ�����Ա�ľ��飬���磺������id���߱�ǩʱ��ʹ�ô�DOM����������Զ�Ǹ���ķ�ʽ��
����û������֧��Xpath����ʽ�����ǿ���ʹ���������루������prototype�⣩��
if (typeof document.evaluate === "function") {
function getElementsByXPath(expression, parentElement) {
var results = [];
var query = document.evaluate(expression,
parentElement || document,
null, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null);
for (var i = 0, length = query.snapshotLength; i < length; i++)
results.push(query.snapshotItem(i));
return results;
}
}��Ȼʹ��Xpath���Խ���κ�ѡ������⣬��������һ�����еķ���������һ����CSSѡ�������ʽ����Ӧ��Xpath�ı���ʽȴ��������η�ĸ��ӡ� �����������չʾ����ΰ�CSSѡ���ת����Xpath����ʽ��
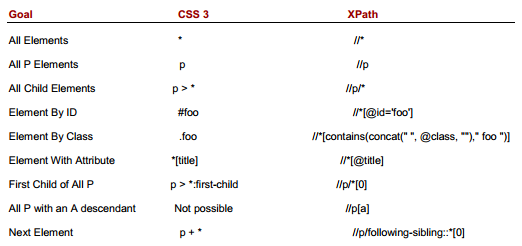
������һ�������������ʽ��CSSѡ�������ʱ�����ǿ�����Xpath�ķ�ʽ��Ϊһ����ģ�飬�����û���ѯ��CSSѡ�������ʽ����ת����Xpath�ı���ʽ��Ȼ��ʹ��Xpath�İ취����DOM��
ʵ��XPath�IJ��ֵĴ���������������ʽ��ʽ�Ĵ���һ���ࡣ�ܶ����Աѡ������XPath�IJ���������CSSѡ�������ĸ��ӳ̶ȡ����ԣ�����Ҫ����Xpath�����ĵ����������Լ����Ĵ���ʵ�ָ��ӳ̶ȡ�
��DOMʵ�ַ�ʽ
CSSѡ�������ĺ������Դ�DOM������ʽʵ�ֵġ��������û�������CSSѡ�����Ȼ��ʹ�����е�DOM����������getElementById, getElementsByTagName�������Ҷ�Ӧ��DOMԪ�ء�ʹ�ô�DOM��ʽʵ�����������ɣ�
��һ��Internet Explorer 6 and 7������IE8���ϵİ汾֧��querySelectorAll()������������IE6��7�ж�Xpath��ѡ���API��֧��ʹ��ʹ�ô�DOMʵ�ֺ��б�Ҫ��
�ڶ������¼��ݣ������ϣ����Ĵ����ܹ���������֧���ϰ汾�������������Safari 2������ô��Ӧ��ʹ�ô�DOMʵ�֡�
������Ϊ���ٶȡ�����ijЩCSSѡ�������ʽ��ʹ�ô�DOM�����ܹ������ø��죨�������id��Ԫ�أ���
֪����ʹ�ô�DOM���ĵ���Ҫ�ԣ�����������Ҫ�������ַ�ʽʵ��ѡ������棺�������½������ʹ������Ͻ�����
һ���������µ���������������CSSѡ�������ʽ�ģ��������ҵ�ƥ��Ԫ�أ���ǰ���ֵĻ������ٽ������²���ƥ���Ԫ�ء� ���ַ�ʽ��Ŀǰ����JavaScript���ʵ�ַ�ʽ����ͨ�õأ�Ҳ��Ѱ��ҳ��Ԫ�ص���ѷ�ʽ�� ����������һ�α��
<body>
<div></div>
<div class="ninja">
<span>Please </span>
<a href="/ninja"><span>Click me!</span>
</a>
</div>
</body>���������ѡ"Click me!"�Ǹ�Ԫ�أ����ǿ�������д ѡ�������ʽ �� div.ninja a span ��
ʹ�ô������µķ����������������ѡ�������ʽ�ģ�
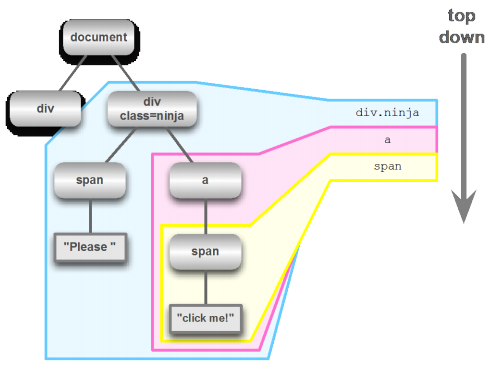
����ʽ�еĵ�һ�div.ninja ָ�����ĵ��е�һ�����������ǿ������У������ұ���ʽ����һ���Ӧ�����������span��Ŀ��ڵ㱻�ҵ���
ע�⣬��ֻ�������������κβ���ƽ������У���ȫ�п����ж������ͬʱƥ�����ʽ����ʵ��ѡ��������ʱ��������ԭ����Ҫ���ǣ�
���صĽ����Ԫ�ص�˳��Ӧ�ð������ĵ���ԭ����˳�����
���صĽ���е�Ԫ�ز�Ӧ�����ظ��ģ����粻��һ��Ԫ���ڽ���г������Σ�
Ϊ�˱�����Щ���壬����Ĵ���ʵ�ֿ��ܻ���һ��С���ɡ�������һ����top-down��ʽ���棬��ֻ�ܹ�֧�ְ���tag��ǩ���ֲ���Ԫ�ء�
<div>
<div> <span>Span</span>
</div>
</div>
<script>
window.onload = function () {
function find(selector, root) {
root = root || document;
var parts = selector.split(" "),
query = parts[0],
rest = parts.slice(1).join(" "),
elems = root.getElementsByTagName(query),
results = [];
for (var i = 0; i < elems.length; i++) {
if (rest) {
results = results.concat(find(rest, elems[i]));
} else {
results.push(elems[i]);
}
}
return results;
}
var divs = find("div");
assert(divs.length === 2, "Correct number of divs found.");
var divs = find("div", document.body);
assert(divs.length === 2,
"Correct number of divs found in body.");
var divs = find("body div");
assert(divs.length === 2,
"Correct number of divs found in body.");
var spans = find("div span");
assert(spans.length === 2, "A duplicate span was found.");
};
</script>������������У�����ʵ����һ����֧�ְ���tag��ǩ���ֲ���Ԫ�صĴ������½�����ʽ��ѡ������档 ���������Էֽ�Ϊ�����Ӳ��֣�����ѡ�������ʽ�����ĵ��в���Ԫ�أ�����Ԫ�أ��ݹ�/�ϲ�ÿһ����Ľ����
����ѡ�������ʽ
������������У��������̾��ǰ�CSSѡ���������"div span"���ֽ���ַ������飨["div", "span"]����ʵ���ϣ���CSS2��CSS3�ı��У�ʹ������ֵ����Ԫ���DZ�֧�ֵġ������ѡ�������ȫ�п����ж���Ŀո�ʹ������ķ����������ˡ����ǣ����ּķ������ڴ����ֵ�����Ѿ��㹻�ˡ�
Ҫ��ȫʵ�ֽ�����������Ҫһϵ�еĽ��������������û��������κα���ʽ�� ����Ĵ������ʹ���������ʽ�ѱ���ʽ�ֽ�ɸ���С�飨�����Ҫ����ֿ����ţ�
<script type="text/javascript">
var selector = "div.class > span:not(:first-child) a[href]"
var chunker = /((?:\([^\)]+\)|\[[^\]]+\]|[^ ,\(\[]+)+)(\s*,\s*)?/g;
var parts = [];
// Reset the position of the chunker regexp (start from beginning)
chunker.lastIndex = 0;
// Collect the pieces
while ((m = chunker.exec(selector)) !== null) {
parts.push(m[1]);
// Stop if we've countered a comma
if (m[2]) {
extra = RegExp.rightContext;
break;
}
}
assert(parts.length == 4,
"Our selector is broken into 4 unique parts.");
assert(parts[0] === "div.class", "div selector");
assert(parts[1] === ">", "child selector");
assert(parts[2] === "span:not(:first-child)", "span selector");
assert(parts[3] === "a[href]", "a selector");
</script>��Ȼ����δ���֧�ֵ�ѡ���ֻ��һ�Ŵ�ƴͼ�е�һС���֡�������Ҫ�������Ľ���������֧���û�����ĸ��ֱ���ʽ��ϡ��������CSSѡ�������ʹ����map�ṹ�������������ʽ��Ӧ��Ŀ�괦��������������һ���������ʽƥ���û�����ʽ��һ����ʱ����Ӧ�ĺ�����ȥ������һ���ֱ���ʽ��ѡ�����
Ѱ��Ԫ��
��ҳ����Ѱ����ȷ��DOMԪ���������ֽ��������ʹ�����ַ���ȡ���������֧��ʲô����ѡ�����
������ getElementById() ��������ֻ��HTML�ĵ��ĸ��ڵ��ϴ��ڡ������������ҵ���һ��ƥ��ָ��idֵ��Ԫ�أ����������������� "#id" �����ı���ʽ��ע�⣬��Internet Explorer �� Opera����ͬ��Ҳ����ҵ�һ������ͬ�� nameֵ��Ԫ�ء� ��ˣ������Ҫֵ���� id ֵ���ң�������Ҫ�����һ����֤�������ų��� nameֵͬ����Ԫ�ء�
�����Ҫ֧��Ѱ�����о��и��� idֵ��Ԫ�أ�����CSSѡ�������ʽ����ϰ�����÷�������HTML�ķ��涨һ��idֻ�ܶ�Ӧһ��Ԫ�أ��������ַ������Բ��ã���һ�ַ������������е�Ԫ�أ��ҳ�����ƥ����� idֵ��Ԫ�أ��ڶ��ַ�����ʹ�� document.all["id"] ����������һ������ƥ��idֵԪ�ص����顣
�������� getElementsByTagName() �������������þ���ͬ���������������ҳ�����ƥ�������ǩ����Ԫ�ء� ע�⣬��������һ���÷������ʹ�� �Ǻ�* ��Ϊ������ǩ������ô���᷵���ĵ��л���һ���ڵ������е�Ԫ�ء� ��һ�ж��� ������������ֵ��ѡ��� �����ã����� ".class" ���� "[attr]"�� ��Ϊ ".class" ��û��ָ����ǩ��������������Ҫ�г�ij�ڵ��µ�������Ԫ�أ�Ȼ�������ж�class���ơ�
���⣬��Internet Explorer��ʹ�� �Ǻ�* ������һ��ȱ�㣬��ͬ���᷵�� ע����� �ڵ㣨��Ϊ��IE�У�ע�����ڵ���һ�� "!" �ı�ǩ����������Ҳ�ᱻ���أ��� ������������Ҫ�����һ�����˹������ų�ע�����ڵ㡣
�������� getElementsByName() ��������������ֻ��һ���� �ҳ�����ƥ����� nameֵ�Ľڵ㣨���磬<input> Ԫ�ض�����nameֵ ������������������������� "[name=name]" �����ı���ʽ��
����� getElementsByClassName() ���������������ԱȽ��£����ڱ������������ʵ�֣�Firefox 3+, Safari 3+ �� Chrome�������������ǻ��� Ԫ�ص�class���� ���в��ҡ� ���������ԭ���ķ�������ؼӿ��� ��class���Ʋ��� �Ĵ���ʵ�֡�
���ܻ���һЩ���������������Ԫ�ز��ң�������Щ������Ȼ��������Ҫʹ�õĹ��ߡ�һ���ҳ�������ƥ��ı�ѡԪ�غ������ͽ���Ԫ�ع����ˡ�
����Ԫ��
һ��CSS����ʽͨ�����ɼ���������С������ɵġ����磬����һ������ʽ "div.class[id]" ��������������ɣ� 1. divԪ�� 2. ���и�����class���� 3. ����һ������id������ֵ��
����������Ҫ�ҳ�ѡ����ĵ�һ���֡����磬����������ʽ�У����ǿ�����һ��������divԪ�أ��������������뵽�� getElementsByTagName() �����ҳ�ҳ�������е� <div> Ԫ�ء� �����������DZ������Ԫ�أ�ʹ��ʣ�µ�Ԫ�ؾ��и�����class���ƺ�id����ֵ��
����Ԫ����ѡ��������ʵ�����ձ���ڵ�һ���֡�����ԭ����Ҫ����Ԫ������ֵ����Ԫ����DOM�����������ڵ�Ĺ�ϵ��
�������Թ��ˣ�����Ԫ�ص�DOM���ԣ�ͨ��ʹ�� getAttribute() ��������������֤����ֵ�Ƿ���ڸ���ֵ������class���������DZ�����е�һ���Ӽ������� className ���Բ�����֤����ֵ����
����λ�ù�ϵ���ˣ� ������������ڶ�����ij��Ԫ����ʹ�� ":nth-child(even)" ���� ":last-child" ��ϵı���ʽ�� ��������֧��������CSSѡ�������ô�᷵��һ����Ԫ�صļ��ϡ����⣬���е��������֧�� childNodes��������һ����Ԫ�صļ��ϣ�����Ҳ�������еĴ��ı��ڵ��ע�����ڵ㡣 ʹ���������ַ�����������Ԫ����DOM���е�λ�ù�ϵ���й��ˡ�
ʵ��Ԫ�ع��˹��ܾ�������Ŀ�ģ���һ��������������ṩ���û������Dz�������Ԫ���Ƿ����ijֵ���ڶ������ڲ�����ʱ�����Լ��Ԫ���Ƿ�����û�������ѡ�������ʽ��
�ϲ�Ԫ��
�ڱ��ĵĵ�һ�δ����У����ǿ��Կ���ѡ���������Ҫ�ܹ��ݹ����Ԫ�أ��ҳ����Ԫ�أ��Լ��ϲ����з���Ҫ���Ԫ�أ����շ��ؽ������
���ǣ��ڱ�С���У����dz����Ĵ���ʵ��̫���ˡ�ע��������������ĵ����ҵ������� <span> Ԫ�ء���ˣ�������Ҫ�������һ����飬��ȷ�����ս���������в��ܰ����ظ���Ԫ�ء� �����top-down��ʽ��ѡ��������ж�ʹ��������ȷ��Ԫ��Ψһ�Եķ�����
<div id="test">
<b>Hello</b>, I'm a ninja!</div>
<div id="test2"></div>
<script>
(function () {
var run = 0;
this.unique = function (array) {
var ret = [];
run++;
for (var i = 0, length = array.length; i < length; i++) {
var elem = array[i];
if (elem.uniqueID !== run) {
elem.uniqueID = run;
ret.push(array[i]);
}
}
return ret;
};
})();
window.onload = function () {
var divs = unique(document.getElementsByTagName("div"));
assert(divs.length === 2, "No duplicates removed.");
var body = unique([document.body, document.body]);
assert(body.length === 1, "body duplicate removed.");
};
</script>���е� unique() �����������е�����Ԫ��������һ����������ԣ���������Ƿ��ʹ�����ˣ�������Ԫ�ض�����������ֻʣ���˲��ظ���Ԫ�ء����Ʊ������������㷨�����ڴ����CSSѡ��������м�����
��ĿǰΪֹ�����Ǵ��¾�����һ�� ���ϵ��·�ʽ(top-down)�� CSSѡ������档 ���ڣ��������������һ�ַ�����
���µ��ϵķ�ʽʵ��
����㲻�ÿ���Ψһ��ȷ��Ԫ�أ���ô������Դ��µ��ϵķ�ʽ��bottom-up��ʵ��ѡ����������̡��������̸����ϵ��µķ�ʽ�෴����ϰ���Ž������̵�ͼʾ�������磬���������ı���ʽ "div span"������Ҫ�����ҳ����� <span> Ԫ�أ�Ȼ�����ÿ����ѡԪ�أ����������Ƿ���һ�� <div> ������Ԫ�ء�
�����ķ�ʽ��û�� ���ϵ��µķ�ʽ ���С��������ܹ����õش�����CSSѡ�������ʽ��������ÿ����ѡԪ���϶������ȵı������Ե�̫�ķ�ʱ�����Դ�ˡ�
������µ��Ϸ�ʽ������ܼ������ҵ�CSSѡ�������ʽ�е����һ�����֣�Ȼ���ҳ�ƥ���Ԫ�أ����Ű���һϵ�еĹ��˹�����˵������ϵ�Ԫ�ء�����Ĵ����������һ���̡�
<div>
<div>
<span>Span</span>
</div>
</div>
<script>
window.onload = function () {
function find(selector, root) {
root = root || document;
var parts = selector.split(" "),
query = parts[parts.length - 1],
rest = parts.slice(0, -1).join("").toUpperCase(),
elems = root.getElementsByTagName(query),
results = [];
for (var i = 0; i < elems.length; i++) {
if (rest) {
var parent = elems[i].parentNode;
while (parent && parent.nodeName != rest) {
parent = parent.parentNode;
}
if (parent) {
results.push(elems[i]);
}
} else {
results.push(elems[i]);
}
}
return results;
}
var divs = find("div");
assert(divs.length === 2, "Correct number of divs found.");
var divs = find("div", document.body);
assert(divs.length === 2,
"Correct number of divs found in body.");
var divs = find("body div");
assert(divs.length === 2,
"Correct number of divs found in body.");
var spans = find("div span");
assert(spans.length === 1, "No duplicate span was found.");
};
</script>ע�⣬��������ֻ�ܴ���һ�����ȹ�ϵ�������Ҫ����������ȹ�ϵ����ô��ǰ���״̬����Ҫ����¼������ʹ���������飺��һ�������¼��Ҫ�����ص�Ԫ�أ����е�ijЩԪ�ر����ó�undefined��������Dz���ƥ�����ʽ�����ڶ��������¼��ǰ��Ҫ�����Ե����Ƚڵ㡣
����֮ǰ��������һ����������ȹ�ϵ��֤�������������ܿ��������ǰ��մ��µ��ϵķ�ʽʵ�־Ͳ���Ҫ�ڽ������ȡ���ظ�Ԫ�ص�һ���������Ҳ����һЩ���ơ�����Ϊ���մ��µ��ϵķ�ʽ���ʼ��ʱ��ÿ��Ԫ�ؾ��Ѿ��Ǹ��Զ������ظ����ˣ���������մ��ϵ��µķ�ʽ�������ڵݹ�ʱ����������ص��������ǻ�����ظ���Ԫ�أ�
��
JavaScriptʵ�ֵ�CSSѡ���������һ��ǿ��Ĺ��ߡ��������������ɵ�ʹ������ѡ������ҳ����Ѱ��DOMԪ�ء���������ȫʵ��һ��ѡ�������ʱ�зdz����ϸ����Ҫ���ǣ�����������ڴ��ĸ��ƣ������������ԭ���ķ�������
�ع�һ�±������۵ļ��㣺
�ִ�������Ѿ���ʼʵ�ֶ��� W3C��ѡ���API��֧�֣�������Ȼ�кܳ�һ��·Ҫ��.
���ǵ��������⣬������Ȼ�б�Ҫʵ���Լ���ѡ������档
Ҫ����һ��ѡ������棬���ǿ��ԣ�
���� W3C����ѡ���API
���� XPath
Ϊ����õ����ܣ�ʹ�ô�DOM������ʽ
���ϵ��µķ�ʽ�dz����У���������ҪһЩ��������������ȷ������Ԫ�ز��ظ���
���µ��ϵķ�ʽ�������Ǹ������������������������������ܿ�����
�����������֧��W3C��ѡ�������������ʵ�ֵ�ϸ�ڻ������Ϊ��ȥʽ�ˡ����Ƕ����������Ա��˵����һ��������ܺܿ�ĵ�����
 ϲ��
ϲ��  ��
�� �ѹ�
�ѹ� ��
�� ��
�� ����
����