
ÿ�춼�ڽ����Լ���ʲô������ʲô��ܣ��ɷ���ʶ����ÿ�춼�ڱ���Щ�����ʡ��¼������Ի�.NET��XML�ȵȼ�����Ȼ���ˣ���������Լ��Ļ�������ʵ����������������������һ����ֻ�ܿ�����ǰ�����ܿ�����Զ�ĵط�����Щ���ʵļ����ڸ�������ײ��ԭ����Ҫ��������ѧϰ�������������ƶˣ�����ʵʵ�İѻ���֪ʶѧ�ã�������Щ������Ҫ������Щ�¼���Ҳ�ͺ������ˡ�
Ҫ��д������Ĵ���ͬ��Ҫ��ʵ�Ļ������������Ͳ����㷨ѧ�IJ��ã���ô�Գ�������ܽ����Ż����ϻ�����˵������Ҫ���ܵ���Щ�����㷨���ǻ����еĻ���������Ա��֪��
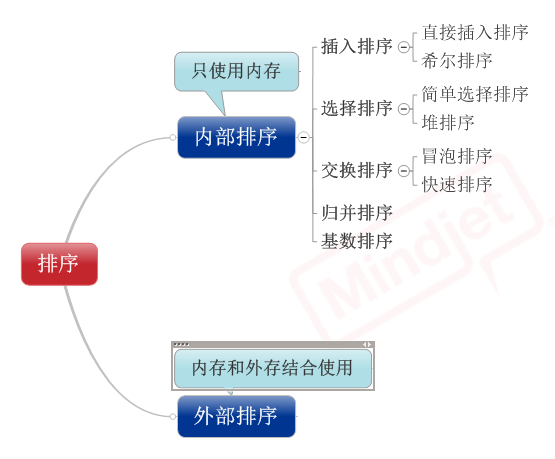
1��ֱ�Ӳ�������
��1������˼�룺��Ҫ�����һ�����У�����ǰ��(n-1) [n>=2] �����Ѿ�����
��˳��ģ�����Ҫ�ѵ�n�����嵽ǰ����������У�ʹ����n����
Ҳ���ź�˳��ġ���˷���ѭ����ֱ��ȫ���ź�˳��
��2��ʵ��

2��ϣ������Ҳ����С��������
��1������˼�룺�㷨�Ƚ�Ҫ�����һ������ij������d��n/2,nΪҪ�������ĸ������ֳ������飬ÿ���м�¼���±����d.��ÿ����ȫ��Ԫ�ؽ���ֱ�Ӳ�������Ȼ������һ����С��������d/2���������з��飬��ÿ�����ٽ���ֱ�Ӳ���������������1ʱ������ֱ�Ӳ��������������ɡ�
��2��ʵ����

3����ѡ������
��1������˼�룺��Ҫ�����һ�����У�ѡ����С��һ�������һ��λ�õ���������
Ȼ����ʣ�µ�������������С����ڶ���λ�õ������������ѭ���������ڶ����������һ�����Ƚ�Ϊֹ��
��2��ʵ����

4��������
��1������˼�룺��������һ������ѡ�������Ƕ�ֱ��ѡ���������Ч�Ľ���
�ѵĶ������£�����n��Ԫ�ص����У�h1,h2,...,hn),���ҽ������㣨hi>=h2i,hi>=2i+1����hi<=h2i,hi<=2i+1��(i=1,2,...,n/2)ʱ��֮Ϊ�ѡ�������ֻ��������ǰ�������Ķѡ��ɶѵĶ�����Կ������Ѷ�Ԫ�أ�����һ��Ԫ�أ���Ϊ�����ѣ�����ȫ���������Ժ�ֱ�۵ر�ʾ�ѵĽṹ���Ѷ�Ϊ��������Ϊ������������������ʼʱ��Ҫ������������п�����һ��˳��洢�Ķ��������������ǵĴ洢��ʹ֮��Ϊһ���ѣ���ʱ�ѵĸ��ڵ�������Ȼ���ڵ���ѵ����һ���ڵ㽻����Ȼ���ǰ��(n-1)�������µ���ʹ֮��Ϊ�ѡ��������ƣ�ֱ��ֻ�������ڵ�Ķѣ��������������������õ���n���ڵ���������С����㷨������������������Ҫ�������̣�һ�ǽ����ѣ����ǶѶ���ѵ����һ��Ԫ�ؽ���λ�á����Զ�����������������ɡ�һ�ǽ��ѵ������������Ƿ�������������ʵ������ĺ�����
��2��ʵ����
��ʼ���У�46,79,56,38,40,84
���ѣ�
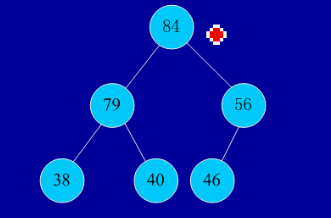
�������Ӷ����߳������

ʣ�����ٽ��ѣ��ٽ����߳������
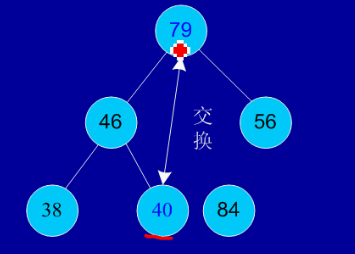
�������ƣ�������ʣ������������㽻�����߳�һ����������ɡ�
5������
��1������˼�룺��Ҫ�����һ�����У��Ե�ǰ��δ�ź���ķ�Χ�ڵ�ȫ���������϶��¶����ڵ����������ν��бȽϺ͵������ýϴ�������³�����С������ð������ÿ�������ڵ����ȽϺ������ǵ�����������Ҫ���෴ʱ���ͽ����ǻ�����
��2��ʵ����

6����������
��1������˼�룺ѡ��һ����Ԫ��,ͨ��ѡ���һ��Ԫ�ػ������һ��Ԫ��,ͨ��һ��ɨ�裬���������зֳ�������,һ���ֱȻ�Ԫ��С,һ���ִ��ڵ��ڻ�Ԫ��,��ʱ��Ԫ�������ź�������ȷλ��,Ȼ������ͬ���ķ����ݹ�����ֵ������֡�
��2��ʵ����

��ͼ�н��������зֳ�������,һ���ֱȻ�Ԫ��С,һ���ִ��ڻ�Ԫ��,Ȼ������������ظ���ͼ�������̡�
����ֻ�ǿ��������һ��ʵ�ַ�ʽ��������Ϊ�Ƚ��������⣩
7���鲢����
��1���������鲢��Merge�������ǽ����������������ϣ�������ϲ���һ���µ�����������Ѵ��������з�Ϊ���ɸ������У�ÿ��������������ġ�Ȼ���ٰ����������кϲ�Ϊ�����������С�
��2��ʵ����

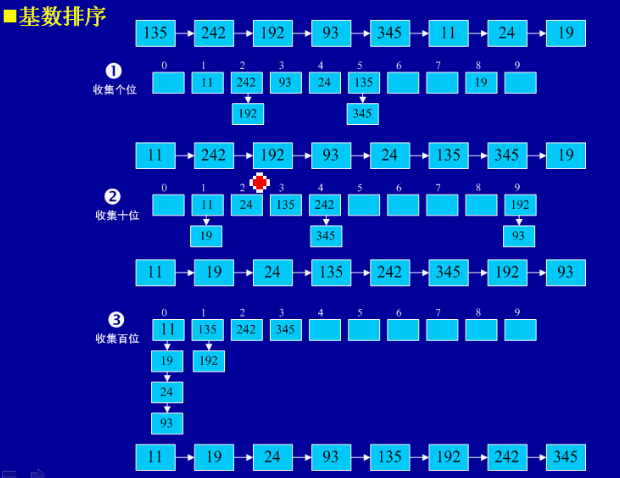
8����������
��1������˼�룺�����д��Ƚ���ֵ����������ͳһΪͬ������λ���ȣ���λ�϶̵���ǰ�油�㡣Ȼ�����λ��ʼ�����ν���һ���������������λ����һֱ�����λ��������Ժ�,���оͱ��һ���������С�
��2��ʵ����
�ȶ���˵��������ǰ��2�����߸��ࣩ����ȵ��������е�ǰ��λ��˳�������������������е�ǰ��λ��˳��һ����
ʵ����
����������5,4,8,6,1,8,7,9
��������1,4,5,6,7,8,8,9
�ȶ���1,4,5,6,7,8,8,9
���ȶ���1,4,5,6,7,8,8,9
˵�����ԱȺ�ɫ��8����ɫ��8������������ǰ���λ�á�����ǰ����8����8ǰ�棬���������8��Ȼ����8ǰ�棬�������㷨�ȶ��������ȶ���
�������Ƿ���һ��8�������㷨���ȶ��ԡ�
�������ѽ��ǰ����������˼��������������ȶ��ԣ�8������Ļ���˼���Ѿ���ǰ��˵�������ﲻ��������Ȼ������Щģ����
��1��ֱ�Ӳ�������һ��������Ƚ��Ǵ��������е����һ��Ԫ�ؿ�ʼ�������������ֱ�Ӳ���������棬����һֱ��ǰ�ȡ�����ҵ�һ���Ͳ���Ԫ����ȵģ���ô�Ͳ��뵽������Ԫ�صĺ��档�����������ȶ��ġ�
��2��ϣ������ϣ�������ǰ��ղ�ͬ������Ԫ�ؽ��в�������һ�β����������ȶ��ģ�����ı���ͬԪ�ص����˳���ڲ�ͬ�IJ�����������У���ͬ��Ԫ�ؿ����ڸ��ԵIJ����������ƶ����ȶ��Ծͻᱻ�ƻ�������ϣ�������ȶ���
��3����ѡ��������һ��ѡ�������ǰԪ�ر�һ��Ԫ��С������С��Ԫ���ֳ�����һ���͵�ǰԪ����ȵ�Ԫ�غ��棬��ô�������ȶ��Ծͱ��ƻ��ˡ���˵�����е�ģ����������Сʵ����858410����һ��ɨ�裬��1��Ԫ��8���4��������ôԭ������2��8�����ǰ��˳���ԭ���в�һ���ˣ�����ѡ�������ȶ���
��4������������Ĺ����Ǵӵ�n/2��ʼ�����ӽڵ㹲3��ֵѡ�����(��)������С(С����),��3��Ԫ��֮���ѡ��Ȼ�����ƻ��ȶ��ԡ�����Ϊn/2-1, n/2-2, ...��Щ���ڵ�ѡ��Ԫ��ʱ���п��ܵ�n/2�����ڵ㽻���Ѻ���һ��Ԫ�ؽ�����ȥ�ˣ�����n/2-1�����ڵ�Ѻ���һ����ͬ��Ԫ��û�н��������Զ������ȶ���
��5��ð��������ǰ������ݿ�֪��ð�����������ڵ�����Ԫ�رȽϣ�����Ҳ������������Ԫ��֮�䣬�������Ԫ����ȣ����ý���������ð�������ȶ���
��6����������������Ԫ�غ�������һ��Ԫ�ؽ�����ʱ���п��ܰ�ǰ���Ԫ�ص��ȶ��Դ��ҡ����ǿ�һ��Сʵ����6 4 4 5 4 7 8 9����һ����������Ԫ��6�͵�����4�����ͻ��Ԫ��4��ԭ�����ƻ������Կ��������ȶ���
��7���鲢�����ڷֽ�������У���1����2��Ԫ��ʱ��1��Ԫ�ز��ύ����2��Ԫ�������С���Ҳ���ύ���������кϲ��Ĺ����У����������ǰԪ�����ʱ�����ǰѴ���ǰ������е�Ԫ�ر����ڽ�����е�ǰ�棬���ԣ��鲢����Ҳ���ȶ��ġ�
��8�����������ǰ��յ�λ������Ȼ���ռ����ٰ��ո�λ����Ȼ�����ռ����������ƣ�ֱ�����λ����ʱ����Щ�����������ȼ�˳��ģ��Ȱ������ȼ������ٰ������ȼ��������Ĵ�����Ǹ����ȼ��ߵ���ǰ�������ȼ���ͬ�ĵ����ȼ��ߵ���ǰ������������ڷֱ����ֱ��ռ����������ȶ��ġ�
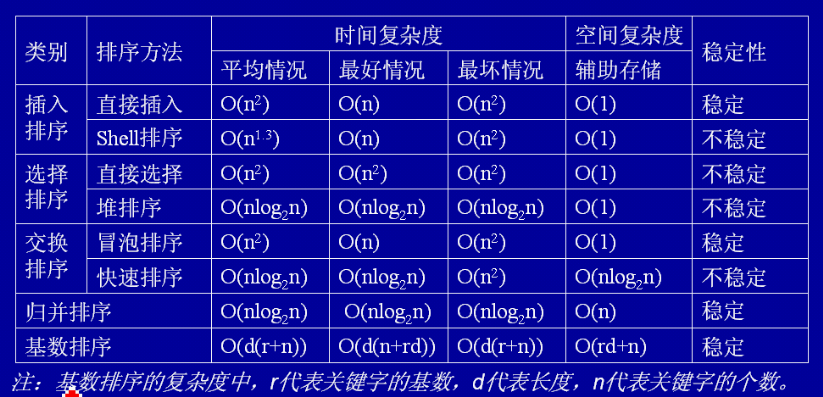
8������ķ��࣬�ȶ��ԣ�ʱ�临�ӶȺͿռ临�Ӷ��ܽ
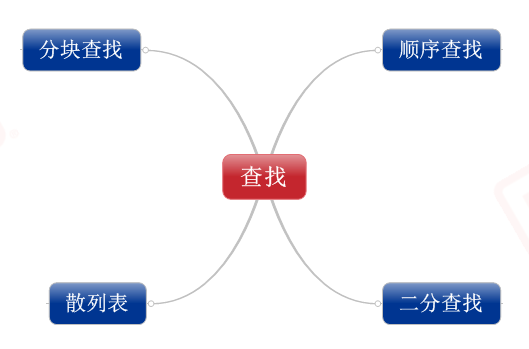
���ֲ����㷨:˳����ң����ַ����ң��۰���ң����ֿ���ң�ɢ�б����Ժ�̸��
һ��˳����ҵĻ���˼�룺
�ӱ���һ�˿�ʼ��˳��ɨ��������ν�ɨ�赽�Ľ��ؼ��ֺ���ֵ���ٶ�Ϊa����Ƚϣ�����ǰ���ؼ�����a��ȣ�����ҳɹ�����ɨ���������δ�ҵ��ؼ��ֵ���a�Ľ�㣬�����ʧ�ܡ�
˵���˾��ǣ���ͷ��β��һ��һ���رȣ�������ͬ�ľͳɹ����Ҳ�����ʧ�ܡ������Ե�ȱ����Dz���Ч�ʵ͡�
���������Ա���˳��洢�ṹ����ʽ�洢�ṹ��

����ƽ�����ҳ��ȡ�
�����ϱ�������1����Ҫ1�Σ�����2��Ҫ2�Σ����������ƣ���֪����16��Ҫ16�Σ�
���Կ���������ֻҪ����Щ���Ҵ�����ͣ����dz���ѧ�ģ��ϵ��µ׳��Ը߳���2����Ȼ����Խ��������Ϊƽ�����ҳ��ȡ�
��n=�ڵ���
ƽ�����ҳ���=��n+1��/2
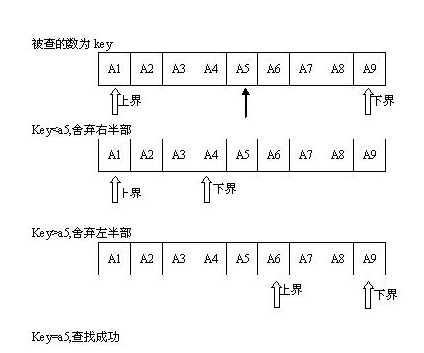
�������ַ����ң��۰���ң��Ļ���˼�룺
ǰ�
��1��ȷ����������е�λ�ã�mid=��low+high��/2
min���������м�Ľ���λ�ã�low��������������λ�ã�high�����������ҽ��λ��
��2��������aֵ����mid�Ĺؼ��֣�������R[mid].key���Ƚϣ�����ȣ�����ҳɹ�������ȷ���µIJ������䣺
���R[mid].key>a�����ɱ��������Կ�֪��R[mid].key�Ҳ��ֵ������a�����Ե���a�Ĺؼ���������ڣ���Ȼ��R[mid].key��ߵı��С���ʱhigh=mid-1
���R[mid].key<a,�����a�Ĺؼ���������ڣ���Ȼ��R[mid].key�ұߵı��С���ʱlow=mid
���R[mid].key=a������ҳɹ���
��3����һ�β�������µIJ������䣬�ظ����裨1���ͣ�2��
��4���ڲ��ҹ����У�low�����ӣ�high���٣����high<low�������ʧ�ܡ�
ƽ�����ҳ���=Log2(n+1)-1
ע����Ȼ���ַ����ҵ�Ч�ʸߣ�����Ҫ�������ؼ���������������һ�ֺܷ�ʱ�����㣬���Զ��ַ��Ƚ�������˳��洢�ṹ��Ϊ���ֱ��������ԣ���˳��ṹ�в����ɾ���������ƶ������Ľ�㡣��ˣ����ֲ����ر�����������һ�������ͺ��ٸĶ����־�����Ҫ���ҵ����Ա���
�����ֿ���ҵĻ���˼�룺
���ֲ��ұ�ʹ�ֿ���������Ա�������������ȡ�����е����ؼ��ּ�����ʼλ�ù���������
����ɣ����ڱ��Ƿֿ�����ģ�������������һ���������������˲���˳�����ֲ�������������ȷ������������һ�飬���ڿ�������ֻ����˳����ҡ�
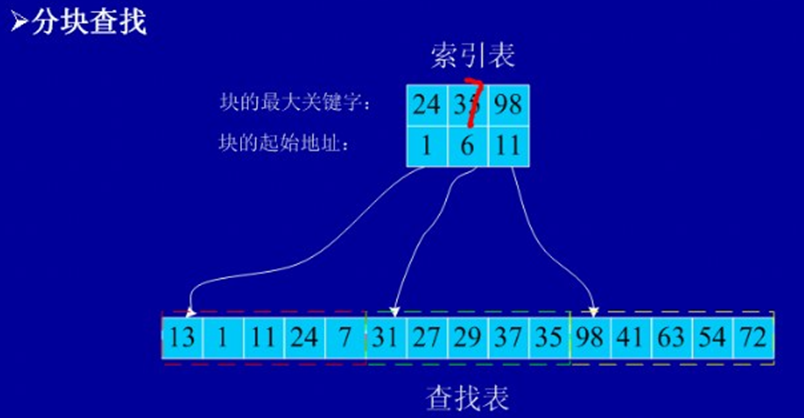
�����n����㣬��b�飬s=n/b
(�ֿ����������)ƽ�����ҳ���=Log2��n/s+1��+s/2
(˳�����������)ƽ�����ҳ���=(S2+2S+n)/(2S)
ע���ֿ���ҵ��ŵ����ڱ��в����ɾ��һ����¼ʱ��ֻҪ�ҵ��ü�¼�����飬���ڸÿ��н��в����ɾ�����㣨������������Բ���Ҫ�����ƶ���¼��������Ҫ����������һ����������Ĵ洢�ؼ��ͽ���ʼ���ֿ���������㡣
�������ܽ���˳����ҺͶ��ֲ���֮�䡣
�ġ�����Ƚ�æ�������Ҹ�ʱ�仹��̸̸ɢ�б�����ϣ����������ϣ����ҹ�ע��
ɢ�б����Ҽ�����ͬ��˳����ҡ����ֲ��ҡ��ֿ���ҡ������Թؼ��ֵıȽ�Ϊ��������������ֱ��Ѱַ����������������£������καȽϾͿ����ҵ�����ؼ��֣����ҵ�����ʱ��ΪO(1)��
 ϲ��
ϲ��  ��
�� �ѹ�
�ѹ� ��
�� ��
�� ����
����



