
ЧАбд
БраДИпадФмЕФе§дђБэДяЪНЃЌгаШчЯТМИЬѕЙцдђЃЌетМИЬѕЙцдђЪЧБОШЫзмНсГіРДЕФЃК
1ЁЂЪЙгУе§ШЗЕФБпНчЦЅХфЦїЃЈ^ЁЂ$ЁЂ\bЁЂ\BЕШЃЉ
2ЁЂЪЙгУОпЬхЕФдЊзжЗћЁЂзжЗћРрЃЈ\dЁЂ\wЁЂ\sЕШЃЉ
3ЁЂЪЙгУе§ШЗЕФСПДЪЃЈ+ЁЂ*ЁЂ?ЁЂ{n,m}ЃЉ
4ЁЂЪЙгУЗЧВЖЛёзщЁЂдзгзщ
5ЁЂзЂвтСПДЪЕФЧЖЬз
ЦфЪЕе§дђБэДяЪНЕФКмЖргХЛЏММЧЩЖМЪЧЮЇШЦзХЁАМѕЩйЛиЫнЁБетбљвЛИіддђНјаагХЛЏЕФЁЃ
жСгкЪВУДЪЧЁАЛиЫнЁБЃЌБЪепОЭВЛдкетРяжиИДСЫЃЌвдЯТЭЈЙ§ОпЬхЕФР§згРэНтетбљЕФЙ§ГЬЁЃ
ЪОР§
вЛЁЂвдЯТЪЧвЛдђЦЅХфЕчзггЪМўЕижЗЕФе§дђБэДяЪНЃК
^\w+([\.-]?\w+)*@\w+([\.-]?\w+)*(\.\w{2,3})+$
ЯШвЛВНВНЕФНтЮіЃК
1ЁЂ^\w+ЃКБэЪОБиаывдзжЗћПЊЪМЃЌ ЧвЪЧвЛИіЛђепЖрИіЃЛ
2ЁЂ([\.-]?\w+)*жаЕФЁА[\.-]?ЁББэЪОЦЅХфЁА.ЁБЛђепЁА-ЁБЃЌСуДЮЛђепвЛДЮЃЛ
3ЁЂ([\.-]?\w+)*жаЕФЁА\w+ЁБдђБэЪОЦЅХфвЛИіЛђепЖрИіЕФзжЗћЃЛ
4ЁЂ([\.-]?\w+)*ећИідђБэЪОЦЅХф.xxxЁЂ-xxxЛђепxxxетбљЕФзжЗћЃЌЧвСуДЮЛђепЖрДЮЃЛ
5ЁЂЕк1-4ВНЃЌдђЦЅХфsunnyЛђепsunny.yangетбљЕФзжЗћЃЛ
6ЁЂЁА@ЁБдђЪЧОпЬхдЊЃЌЦЅХфОпЬхЕФ@ЃЛ
7ЁЂ \w+ЃКдђБэЪОЦЅХфЕФвЛИіЛђепЖрИіЕФзжЗћЃЌвђЮЊemailВЛПЩФметбљТяЃКsunny@.gmail.comЃЛ
8ЁЂ ([\.-]?\w+)*ЃКдђИњЕк2-4ВНвЛбљЃЌЦЅХф.163ЁЂ-libЁЂ.gdетбљЕФзжЗћЃЌЧвСуДЮЛђепЖрДЮЃЛ
9ЁЂ (\.\w{2,3})+$ЃКдђЦЅХф.comЁЂ.ccетбљНсЮВЕФгђУћЃЌЧввђЮЊ\w{2,3}ЯоЖЈСЫГЄЖШБиаыЮЊ2-3ЮЛЃЌЫљвдВЛФмЦЅХф.cЁЂ.nетбљЕФзжЗћЁЃ
еЇПДетбљвЛИіНтЮіЙ§ГЬУЛЮЪЬтЃЌТпМе§ШЗЃЌЕЋЦфЪЕАЕВиКмЖрЮЪЬтЃЌПДПДвдЯТЕФвЛИіЦЅХфЭМЃЌbacktrackдђБэЪОЛиЫнЃЈЪЙгУRegexBuddyПЩвдКмЧхЮњЕФПДЕНетЙ§ГЬЃЉ
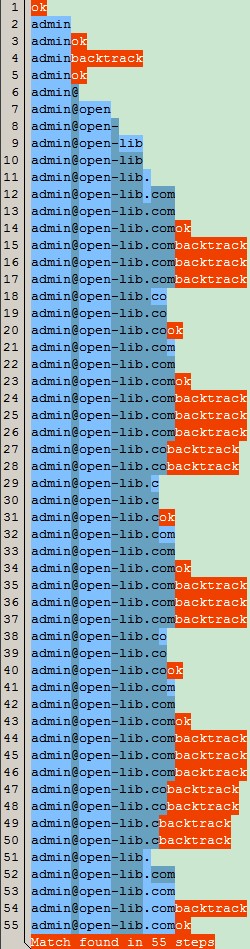
ећИіГЩЙІЕФЦЅХфЙ§ГЬОРњСЫ55ВНЃЌЮвУЧЯШЗжЮіЯТећИіЦЅХфЙ§ГЬЃК
1ЁЂЭМжаЕФЕк1КЭ2ВНЃЌЦЅХф^\w+ЃЌЦЅХфГЩЙІЃЌЦЅХфСЫЁАadminЁБ;
2ЁЂЭМжаЕк3ВНЃЌЦЅХф[\.-]?ЃЌЕБШЛгЩгкВЛДцдкЁА.ЁБКЭЁА-ЁБЃЌвђДЫУЛЦЅХфЩЯОпЬхЕФзжЗћЃЌЕЋгжгЩгкЁА?ЁБЕФЯоЖЈЃЌПЩвдЦЅХфСуЛђепвЛДЮЃЌвђДЫетИізгБэДяЪНЦЅХфГЩЙІЃЌЫфШЛУЛЦЅХфЩЯОпЬхЕФзжЗћЁЃ
3ЁЂЭМжаЕк4ВНЃЌЦЅХф\w+ЃЌгЩгкЁА+ЁБЯоЖЈвЛИіЛђепЖрИівдЩЯзжЗћЃЌЕЋКѓајвбОУЛ[a-zA-Z0-9]ПЩвдЦЅХфСЫЃЌвђДЫВњЩњЛиЫнЃЌЛиЫнЕНЩЯДЮЦЅХфГЩЙІЕФЮЛжУЃЌвВОЭadminЃЛ
4ЁЂЭМжаЕк5ВНЃЌвђЮЊЩЯвЛВНВњЩњСЫЛиЫнЃЌЫљвдЁА[\.-]?\w+ЁБЦЅХфСЫСуДЮЃЌгЩгк([\.-]?\w+)*жаЯоЖЈСуДЮЛђепЖрДЮЃЌвђДЫвВЦЅХфГЩЙІЃЌвВУЛЦЅХфЩЯОпЬхЕФзжЗћЃЛ
вдЯТВНжшЃЌЦЅХфИУЙ§ГЬЃК
^\w+([\.-]?\w+)*@\w+([\.-]?\w+)*(\.\w{2,3})+$
5ЁЂЭМжаЕк6ВНЃЌЦЅХфСЫЁА@ЁБ ЃЌЕк7ВНЦЅХфСЫЁА\w+ЁБЃЌМДЦЅХфСЫЁАopenЁБЃЛ
6ЁЂЭМжаЕк8-13ВНЃЌЦЅХфЁА([\.-]?\w+)*ЁБ ЃЌЦЅХфСЫЁА-libЁБЁЂЁА.comЁБЃЌЦЅХфЁА.comЁБПЩФмгыЮвУЧЦкЭћВЛЯрЗћЃЌЮвУЧЦкЭћетзгБэДяЪНЦЅХфЕФЪЧwww.xx.gd.cnжаЕФЁА.gdЁБЃЛ
7ЁЂЭМжаЕк7-10ВНЃЌЦЅХфСЫopen-libЃЌЕк7-13ВНдђЦЅХфСЫopen-lib.comЃЛ
8ЁЂвђЮЊЁА([\.-]?\w+)*ЁБжаЕФСПДЪЪЧЁА*ЁБЃЌдђМЬајжиИДетИіЙ§ГЬЃЛ
9ЁЂ ЭМжаЕк14ВНЃЌЦЅХфЁА([\.-]?\w+)*ЁБжаЕФЁА[\.-]?ЁБЃЌвђЮЊДЫЪБжИеывбОЮЛгк@open-lib.comжЎКѓСЫЃЌЕЋгЩгкСПДЪЁА?ЁБЃЌвђДЫвВЦЅХфГЩЙІЃЌЕЋУЛЦЅХфЩЯзжЗћЃЌвВУЛзжЗћПЩЦЅХфЃЛ
10ЁЂ ЭМжаЕк15ВНЃЌЦЅХфЁА([\.-]?\w+)*ЁБжаЕФЁА\w+ЁБЃЌДЫЪБжИеыШдЮЛгкзжЗћДЎФЉЮВЃЌУЛШЮКЮзжЗћФмЦЅХфЃЌЫљвдЦЅХфЪЇАмЃЌВњЩњЛиЫнЃЌЛиЕНЩЯДЮГЩЙІЕФЮЛжУЃЌМДЭМжаЕФЕк13ВНЃЌМЬајЯТИіБэДяЪНЕФЦЅХфЃЛ
11ЁЂ ЭМжаЕк16ВНЃЌЦЅХф(\.\w{2,3})+жаЕФЁА\.ЁБЃЌгЩгкУЛгаШЮКЮзжЗћФмЦЅХфЃЌЦЅХфЪЇАмЃЌНјааЛиЫнЃЛ
12ЁЂЭМжаЕк17ВН ЃЌ(\.\w{2,3})+жаСПДЪЁА+ЁБЃЌБэЪОИУБэДяЪНБиаыЦЅХфвЛДЮЛђепЖрДЮЃЌгЩгкЩЯвЛВНЦЅХфЪЇАмСЫЃЌЫљвдЦЅХфСуДЮЃЌЕЋВЛЗћКЯвЛДЮЛђепЖрДЮЕФЯоЖЈЃЌвђДЫМЬајЛиЫнЃЛ
13ЁЂгЩгкЩЯвЛВНЦЅХфЪЇАмЃЌашвЊНјааЛиЫнЃЌвђДЫБэДяЪНУЛгаИќЖрЕФЗжжЇСЫЃЌжЛФмНЋжИеыЛиЭЫвЛИізжЗћЃЌЛиЫнЩЯДЮГЩЙІЕФЮЛжУЃЌМД([\.-]?\w+)*жа\w+ЕФЮЛжУЃЈетЪЧЩЯДЮВњЩњЗжжЇЕФЮЛжУЃЉЃЛ
14ЁЂЭМжаЪЃЯТЕФВНжшЃЌОЭжиИДзХЦЅХф([\.-]?\w+)*ЃЌЛиЭЫзжЗћЃЌЦЅХф(\.\w{2,3})+етбљЕФЙ§ГЬЃЌжБЕНЦЅХфГЩЙІЁЃ
ЖўЁЂвдЯТПДПДСэЭтвЛдђЭЌбљЦЅХфгЪМўЕижЗЕФе§дђБэДяЪНЃК
^\w+([-\.]\w+)*@\w+([-\.]\w+)*\.\w+([-\.]\w+)*$
етИіе§дђИњЩЯУцЕФПДЦ№РДУВЫЦВюВЛЖрЃЌВЛЙ§ЯИПДЛЙЪЧгаЧјБ№ЕФЃЌвВЯШвЛВНВНРДНтЮіЃК
1ЁЂ^\w+ЃКБэЪОБиаывдзжЗћПЊЪМЃЌ ЧвЪЧвЛИіЛђепЖрИіЃЈетвЛВНгыЩЯУцЕФвЛбљЃЉЃЛ
2ЁЂ ([-\.]\w+)*жаЕФЁА[-\.]ЁББэЪОЦЅХфЁА-ЁБЛђепЁА.ЁБЃЛ
3ЁЂ ([-\.]\w+)*жаЕФЁА\w+ЁБдђБэЪОЦЅХфвЛИіЛђепЖрИіЕФзжЗћЃЛ
4ЁЂ([-\.]\w+)*ећИідђБэЪОЦЅХф.xxxЁЂ-xxxетбљЕФзжЗћЃЌЧвСуДЮЛђепЖрДЮЃЛ
5ЁЂЕк1-4ВНЃЌдђЦЅХфsunnyЛђепsunny.yangетбљЕФзжЗћЃЛ
6ЁЂЁА@ЁБдђЪЧОпЬхдЊЃЌЦЅХфОпЬхЕФЁА@ЁБЃЛ
7ЁЂ \w+ЃКдђБэЪОЦЅХфЕФвЛИіЛђепЖрИіЕФзжЗћЃЌвђЮЊemailВЛПЩФметбљТяЃКsunny@.gmail.comЃЛ
8ЁЂ([-\.]\w+)*ЃКдђИњЕк2-4ВНвЛбљЃЌЦЅХф.163ЁЂ-libЁЂ.gdетбљЕФзжЗћЃЌЧвСуДЮЛђепЖрДЮЃЛ
9ЁЂЁА\.ЁБдђЪЧОпЬхдЊЃЌЦЅХфЁА.ЁБЃЛ
10ЁЂ\w+ЃКдђЦЅХфвЛИіЛђепЖрИізжЗћЃЛ
11ЁЂ([-\.]\w+)*ЃКдђЦЅХфЁА.comЁБЁЂЁА-libЁБЁЂЁА.cЁБетбљЕФзжЗћЃЌЧвПЩвдСуДЮЛђепЖрДЮЃЛ
12ЁЂ$ ЃКдђБэЪОНсЮВ
еЇПДетИіе§дђЕФВНжшЙ§ГЬУВЫЦБШЩЯвЛдђГЄЃЌЦфЪЕВЛШЛЃЌЭЌЪБетИіе§дђвВДцдкзХЮЪЬтЃЌЯШПДПДЦЅХфЭМЃЌЭЌбљbacktrackБэЪОЛиЫнЃК
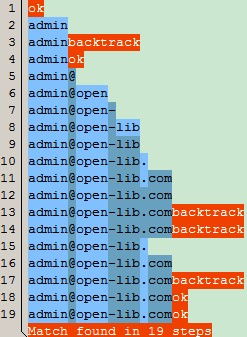
ЖдЕФЃЌФуУЛПДДэЃЌећИіе§ШЗЕФЦЅХфЙ§ГЬгУСЫ19ВНЃЌЖдБШЧАУцЕФ55ВНЃЌМђжБЬьгыЕиЕФВюБ№ЁЃЃЌЮвУЧМЬајЗжЮіЯТЦЅХфЙ§ГЬЃК
1ЁЂЭМжаЕФЕк1КЭ2ВНЃЌЦЅХф^\w+ЃЌЦЅХфГЩЙІЃЌЦЅХфСЫЁАadminЁБ;
2ЁЂЭМжаЕк3ВНЃЌЦЅХф[-\.]ЃЌЕБШЛгЩгкВЛДцдкЁА.ЁБКЭЁА-ЁБЃЌвђДЫУЛЦЅХфЩЯОпЬхЕФзжЗћЃЌвВУЛОпЬхЕФСПДЪдЪаэЦЅХфСуДЮЃЌЫљвдВЛгУМЬајЭљЯТЦЅХфСЫЃЌвђДЫжБНгВњЩњСЫЛиЫнЃЛ
3ЁЂЭМжаЕк4ВНЃЌвђЮЊЩЯвЛВНВњЩњСЫЛиЫнЃЌЫљвдЁА[-\.]\w+ЁБЦЅХфСЫСуДЮЃЌгЩгк([-\.]\w+)*жаЯоЖЈСуДЮЛђепЖрДЮЃЌвђДЫвВЦЅХфГЩЙІЃЌвВУЛЦЅХфЩЯОпЬхЕФзжЗћЃЛ
вдЯТВНжшЃЌЦЅХфИУЙ§ГЬЃК
^\w+([-\.]\w+)*@\w+([-\.]\w+)*\.\w+([-\.]\w+)*$
4ЁЂЭМжаЕк6ВН\w+ЃЌЦЅХфСЫopenЃЛ
5ЁЂЭМжаЕк7-12ВНЦЅХф([-\.]\w+)*ЃЌЦЅХфСЫЁА-libЁБКЭЁА.comЁБЃЛ
6ЁЂвђЮЊЁА([-\.]\w+)*ЁБжаЕФСПДЪЪЧЁА*ЁБЃЌдђМЬајжиИДетИіЙ§ГЬЃЛ
7ЁЂЭМЕк13ВНЃЌЦЅХф([-\.]\w+)* ЃЌвђЮЊДЫЪБжИеывбОЮЛгк@open-lib.comжЎКѓСЫЃЌвВУЛОпЬхЕФСПДЪдЪаэЦЅХфСуДЮЃЌвђДЫЦЅХфЪЇАмЃЌЛиЫнЕНЩЯДЮГЩЙІЕФЮЛжУЃЛ
8ЁЂЭМЕк14ВНЃЌЦЅХф ([-\.]\w+)*$жаЕФЁА[-\.]ЁБЃЌДЫЪБжИеыШдЮЛгкзжЗћДЎФЉЮВЃЌУЛШЮКЮзжЗћФмЦЅХфЃЌЫљвдЦЅХфЪЇАмЃЌВњЩњЛиЫнЃЌЛиЕНЩЯДЮГЩЙІЧвЛЙУЛГЂЪдЙ§ЕФЮЛжУЃЌМДЭМжаЕФЕк9ВНЃЛ
9ЁЂОЙ§ЩЯУцЕФЛиЫнЃЌжИеывбОЮЛгк@open-libжЎКѓЕФЮЛжУСЫЃЛ
10ЁЂЭМЕк15ВНЦЅХфСЫЁА.ЁБЃЌЕк16ВН\w+дђЦЅХфСЫЁАcomЁБ ЃЛ
11ЁЂЭМЕк17ВНЦЅХф([-\.]\w+)*ЃЌгЩгкДЫЪБжИеыгжЮЛгкзжЗћДЎФЉЮВЃЌвђДЫ[-\.]ВПЗжУЛЦЅХфЩЯШЮКЮзжЗћЃЌвђДЫВњЩњЛиЫнЃЛ
12ЁЂЭМЕк18ВНЃЌгЩгк ([-\.]\w+)*ЕФСПДЪЪЧЁА*ЁБЃЌБэЪОЦЅХфСуДЮЛђЖрДЮЃЌЫфШЛзгБэДяЪН[-\.]ЦЅХфЪЇАмЃЌЫљвдећИіБэДяЪНЦЅХфСЫСуДЮЃЌвВЪЧЦЅХфГЩЙІЃЛ
13ЁЂзюКѓвЛВНЕк19ВНЃЌЁА$ЁББэЪОФЉЮВЦЅХфЃЌвђЮЊДЫЪБжИеыЮЛгкзжЗћДЎФЉЮВЃЌЙЪЗћКЯЃЌвђДЫвВЦЅХфГЩЙІЁЃ
ЗжЮі
ећИіЦЅХфЙ§ГЬЙиМќгХЛЏЕиЗНЃЌЛЙЪЧЛиЫнЃЌСНИіЪОР§БэДяЪНПДЦ№РДЯрНќЃЌЦЅХфЙ§ГЬвВВПЗжРрЫЦЃЌЕЋСНИіР§згЕФаЇТЪШДШчДЫДѓЕФЗжБ№ЃЌЯждкРДЗжЮівЛЯТдьГЩЛиЫнЕФдвђЁЃ
ЖдБШЯТСНИіБэДяЪНВЛЭЌЕФВПЗжЃК
^\w+([\.-]?\w+)*@\w+([\.-]?\w+)*(\.\w{2,3})+$
^\w+([\.-]\w+)*@\w+([\.-]\w+)*\.\w+([-\.]\w+)*$
 ЯВЛЖ
ЯВЛЖ  ЖЅ
ЖЅ ФбЙ§
ФбЙ§ х
х ЮЇЙл
ЮЇЙл ЮоСФ
ЮоСФ



