- РраЭЃКаавЕШэМўДѓаЁЃК3.7MгябдЃКжаЮФ ЦРЗжЃК1.4
- БъЧЉЃК
гЩгкЙЄзїашвЊЃЌЙЋЫОШУЮвзівЛИіЙиМќДЪМьВтЙЄОпЃЌОЭЪЧИљОнЙиМќДЪАйЖШЫбЫбЫбЙЗЕШЫбЫїв§ЧцВщбЏЛёШЁХХУћеОЕуЕижЗЕШЯрЙиаХЯЂЕФвЛИіЖЋЮїЁЃЕБЮвНгЕНетИіcaseЕФЪБКђЃЌЪзЯШСЊЯыЕФЪЧвЛЕРУцЪдЬтЃЌОЭЪЧИјФувЛИіhtmlвГУцШУФуМьЫїГіетИівГУцЕФЙиМќаХЯЂЃЌетИіУцЪдЬтЪЧБШНЯМђЕЅЕФЃЌОЭЪЧе§дђЕФЦЅХфЃЌвђДЫЮввВЯыгУе§дђШЅЛёШЁЁЃВЛЙмШ§ЦпЖўЪЎвЛЃЌЪзЯШЪЕЯждйЫЕ

ЦфЪЕетИівбОВЛЪЧзюГѕЕФФЧИіАцБОСЫЃЌзюЙХРЯЕФФЧИіАцБОИФЖЏУцФПШЋЗЧСЫЃЌетИіЦфЪЕОЭЪЧЫФЬѕЯпГЬ
ШЅЖСШЁhtmlШЛКѓЗжЮі ОЭетбљЪЕЯжСЫЁЃ
Й§ГЬжагіЕНЮЪЬтга
УЛгаПМТЧЧхГўашЧѓЃЌвГУцЗжЮіе§дђЮЌЛЄФб
НтОіЗНАИвЛ
| /// <summary> /// ИљОнБъЧЉУћГЦЛёШЁHtml /// </summary> /// <param name="TagName">БъЧЉУћГЦ</param> /// <param name="HTML">html</param> /// <returns>ЗЕЛижЕСаБэ</returns> public List<string> GetHtmlTagByName(string TagName, string HTML) { HTML = Regex.Replace(HTML, @"<\s+", "<", RegexOptions.IgnoreCase); HTML = Regex.Replace(HTML, @"\s+>", ">", RegexOptions.IgnoreCase); HTML = Regex.Replace(HTML, @"</\s+", "</", RegexOptions.IgnoreCase); List<string> TagList = new List<string>(); string Tag = string.Empty; HTML = HTML.ToLower(); int TagLength = TagName.Length; int StartTagLength = TagLength + 2; int EndTagLength = TagLength + 3; List<int> IndexList = new List<int>(); for (int i = 0; i < HTML.Length; i++) { if (HTML[i] == '<') { if ((HTML.Length - i) >= StartTagLength) {//<div> | <div\s string TemTag = HTML.Substring(i, StartTagLength); if (TemTag == '<' + TagName + ' ' || TemTag == '<' + TagName + '>') { IndexList.Add(i); } } if ((HTML.Length - i) >= EndTagLength) {//</div> string TemTag = HTML.Substring(i, EndTagLength); if (TemTag == "</" + TagName + '>') { if (IndexList.Count > 0) { int S = IndexList[IndexList.Count - 1]; IndexList.Remove(IndexList[IndexList.Count - 1]);//вЦГ§зюКѓвЛИі TagList.Add(HTML.Substring(S, (i - S) + EndTagLength)); } } } } } return TagList; } |
етОЭЪЧвЛИіМђЕЅЕФЗНЗЈЛёШЁБъЧЉЖджЎМфЕФШЋВПhtml ЪЕЯжСЫЫљашвЊЕФЙЄФмЃЌЕЋЪЧКІХТЮШЖЈадГіЯжЮЪЬтЃЌЫљвдЦњгУ
ЦњгУжЎКѓжиаТПМТЧЫМТЗ ЛГіСїГЬЭМ
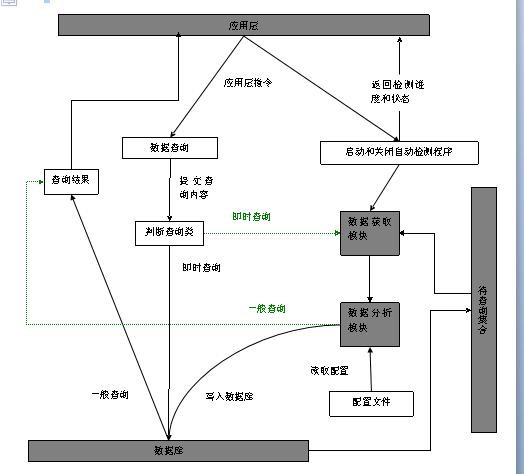
етбљЫМТЗИќМгЧхЮњСЫ вВПМТЧСЫХфжУЕФЮЊЬт ШнвзаоИФ ХфжУНиЭМ

зіЭъХфжУвдКѓЦфЪЕОЭЪЧПМТЧНгПкЪЕЯжНгПкзіГізюжеЕФАцБО
ВтЪдНиЭМ
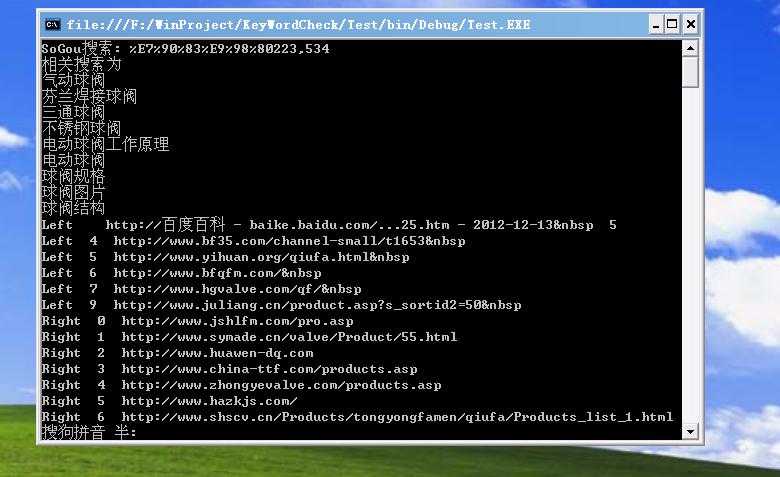
ећИіЙ§ГЬжаЃЌЮвОѕЕУздМКГіЯжЕФзюДѓЮЪЬтОЭЪЧ ПМТЧЮЪЬтНЧЖШЮЪЬтЃЌЮввђЮЊУЛгазіЙ§ ОЭЯызХШчКЮШЅЪЕЯжЃЌдкзіЕФЙ§ГЬжаЗЂЯжКмЖрЮЪЬт дйШЅРЉеЙ зюКѓДњТыЯрЕБЛьТв вВаэвЛИідТКѓЮвздМКШЅаоИФЖМВЛФмЭъГЩСЫЁЃвдКѓвЛЖЈвЊЯШПМТЧКУМмЙЙ(ЙУЧветУДЫЕАЁ)ЃЌЪЕЯжШчЙћГіЯжЮЪЬтЪЧПЩвдНтОіЕФЁЃ
ЪеЛё:ДгФкВПвЛВНВНЭљЭтРЉеЙЃЌВЛШчДгЭтВПвЛВНВНЭљФкВПЩюШыЃЁ
етИіВюВЛЖрЪЧзмНсСЫАЩЃЌОЭетбљСЫАЩЃЌЮвЛЙвЊзіДњТыгХЛЏЁЃ
СэЭтШчЙћгаШЫашвЊетЗНУцЕФзЪСЯ ЛђепетИіЙЄОпЮвЖМПЩвдИјФуЃЌетИіжЛЪЧЙЋЫОЙЄзїЕФвЛИіаЁВхМўАЩЃЌММЪѕКЌСПвВУЛгаЃЌжївЊЪЧе§дђ ЃЌЮвУЧЛЙПЩвдНЛСїЁЃ
 ЯВЛЖ
ЯВЛЖ  ЖЅ
ЖЅ ФбЙ§
ФбЙ§ х
х ЮЇЙл
ЮЇЙл ЮоСФ
ЮоСФ